![]()
![]()
![]()
|
|
Универсальный учебник иностранных языков
(начало публикации - октябрь 2011 г. - обновление 08.10.2018)
Введение
Данный учебник иностранных языков основан на исследовательских материалов многих языков, таких как латинский, греческий, английский, французский, немецкий, испанский, иврит, санскрит и других, которые видятся в перспективе анализа. Учебник рекомендуется в качестве приложения для изучения иностранных языков для широкого круга читателей. Большинство учебников иностранного языка построены по единому принципу изложения грамматики языка, которая включает фонетику, морфологию и синтаксис. Фонетика состоит из следующих частей: - алфавит; - гласные; - согласные; - дифтонги; - слоги; - особенности ударения; - фонетические законы. Морфология в свою очередь включает части речи: - имя существительное; - имя прилагательное; - служебные слова (детерминативы); - имя числительное; - местоимение; - глагол; - наречие; - предлог; - союз; междометие. Синтаксис состоит из следующих разделов : - предложение; - порядок слов; - способы выделения членов предложения; - сложное предложение; - косвенная речь. Все эти разделы сдобрены различным количеством примеров и текстов для заучивания и объяснением преимущества использования данного учебника. В последнее время в учебниках появилась русифицированная транскрипция, которая по мнению авторов значительно улучшает усвояемость материала. Есть учебник, который выпадает из общего контекста обучения и использует метод ассоциативного мышления для запоминания слов. Это метод перспективный, я сам когда-то пробовал его в юности для запоминания слов. Однако все существующие учебники иностранных языков и учебник, основанный на методе ассоциативного мышления, зиждятся на запоминании и зубрёжке слов, как ты не крути. Мой учебник предлагает совсем иную методику, не требующий запоминания слов и изучения фонетики. Мой метод учит понимать происхождение слова. Зная этимологию слов, вы легко поймёте, что мировые языки произошли от одного праязыка, имеющего корни для всех ныне существующих языков. Этот праязык называется ностратическим языком. Слово «ностра» – nostra - наш (лат.). Но и по-славянски nostra > nashij – наший, наш (праслав.)(редукция sh/st, замена j/r). Мы видим, что путём некоторых преобразований слова мы получаем славянский корень слова равный по значению латинскому слову. Внешне разные по звучанию слова имеют оказывается одинаковый смысл. Это и есть моя методика. Зная способы преобразования слова можно понять чужое, иностранное слова без необходимости его заучивать. Приведём пример из известного и популярного учебника А. Н. Драгункина. « «You Can Carry More with Less Effort !» Транскрипция : юу коен каери моо wиð лес эфэт «Вы с/можеТе носиТЬ больше с меньшИМИ усилиЯМИ !» Все английские слова, участвующие в этом предложении, могут просто взяты из словаря или один раз и навсегда ВЫЗУБРЕНЫ, так как НИ ОДНО ИЗ НИХ НЕ ПОДВЕРГЛОСЬ НИКАКИМ ИЗМЕНЕНИЯМ !» [1]. Эта прогрессивная методика изучения английского языка требует зубрёжки и постоянного лазания в словарь. Как это предложение мы можем протичать без обращения к словарю и зубрёжке, зная правила преобразования слов ? Транскрипция на латыни : «Ti moge nositi bolej [wi]s malijj ussilij !»
Метод поиска славянских корней : can > moge – може (праслав.)(инв. can, замена n/m, g/c) carry > nositi – носити (праслав.)(инв. carry, замена n/r, редукция s/c) moo > bolej - более (праслав.)(редукция b/m, пропуск l) less – malijj – малый (праслав.)( пропуск m, редукция j/s) effort > ussilij – усилий (праслав.)(замена s/f, редукция l/r, замена j/t)
Перевод на русский с праславянского: «Ти може носити болей с малый усилий !»
Метод поиска славянских корней :
You > Ti – ты (праслав.)(замена t/y, i/u) can > moge – може (праслав.)(инв. can, замена n/m, g/c) carry > nositi – носити (праслав.)(инв. carry, замена n/r, редукция s/c) moo > bolej - более (праслав.)(редукция b/m, пропуск l) less – malijj – малый (праслав.)( пропуск m, редукция j/s) effort > ussilij – усилий (праслав.)(замена s/f, редукция l/r, замена j/t)
Адаптированный перевод : «Ты можешь носить больше с меньшими усилиями !»
Другой пример из французского языка [11]: «Je aime le fromage» Перевод с французского : «Я люблю сыр» Транскрипция на латыни : «Ja lubij tvorogij» Метод поиска славянских корней : Je > Ja – я (праслав.) aime > lubij – любый (праслав.)( пропуск l, редукция b/m). fromage – tvorogij – творожий (праслав.)(замена t/f, v/r, r/m, j/e), примечание : артикля la в праязыке нет (можно сказать toj – этот). . Перевод на русский с праславянского: «Йа любый творожий» Адаптированный перевод : «Я люблю творожный (сыр)»
На старофранцузском предложение будет иметь следующее написание : «Je aime le sromage», где буква f заменена на s. Перевод будет ещё более близок к реальному «Ja lubij siranij»- «я люблю сырный (сыр)».
Поверьте мне, я не пользовался словарём английского или французского языка, я просто знаю русский язык, в том числе и бытовую лексику русского языка и предшествующий ему древнеславянский (церковнославянский или старославянский) язык, который мы обязаны знать. Приступая к исследованию немецкого языка, я думал, что столкнусь с проблемами поиска славянских корней (уж очень разная фонетика), но результаты превзошли все ожидания. Немецкие слова оказались на удивление слишком доступные (специально выбраны самые длинные слова):
Таблица 1
Примеры из китайского языка : Примечание : языки в которых буквы и слоги существуют в графической (иероглифической) форме, такие как китайский, арабский и др. представлены в международной (латинизированной) транскрипции.
Продолжение табл. 1
Можно подогнать по звучанию одно, десяток слов, но нельзя это сделать с сотнями слов (см. китайско-праславянский словарь на сайте). Практически все китайские слова имеют славянские корни ! В тоже время, древнеславянский язык не является начальной стадией славянского языка, а является всего лишь переходной ступенью более древнего славянского языка, вероятнее всего венедского. Венедский язык, в свою очередь, произошёл от этрусского языка, который тоже имеет глубокие корни происхождения. Следовательно, глубина познания русского языка очень велика и в полной мере не исследована.
История происхождения славянской азбуки
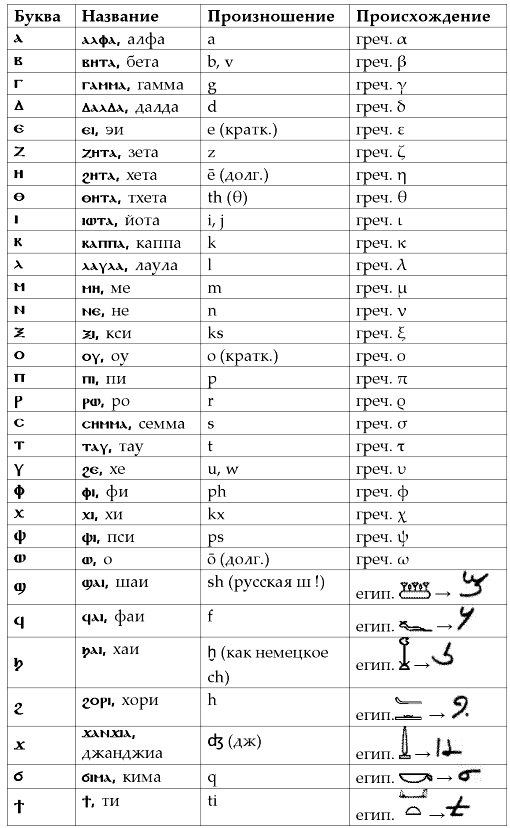
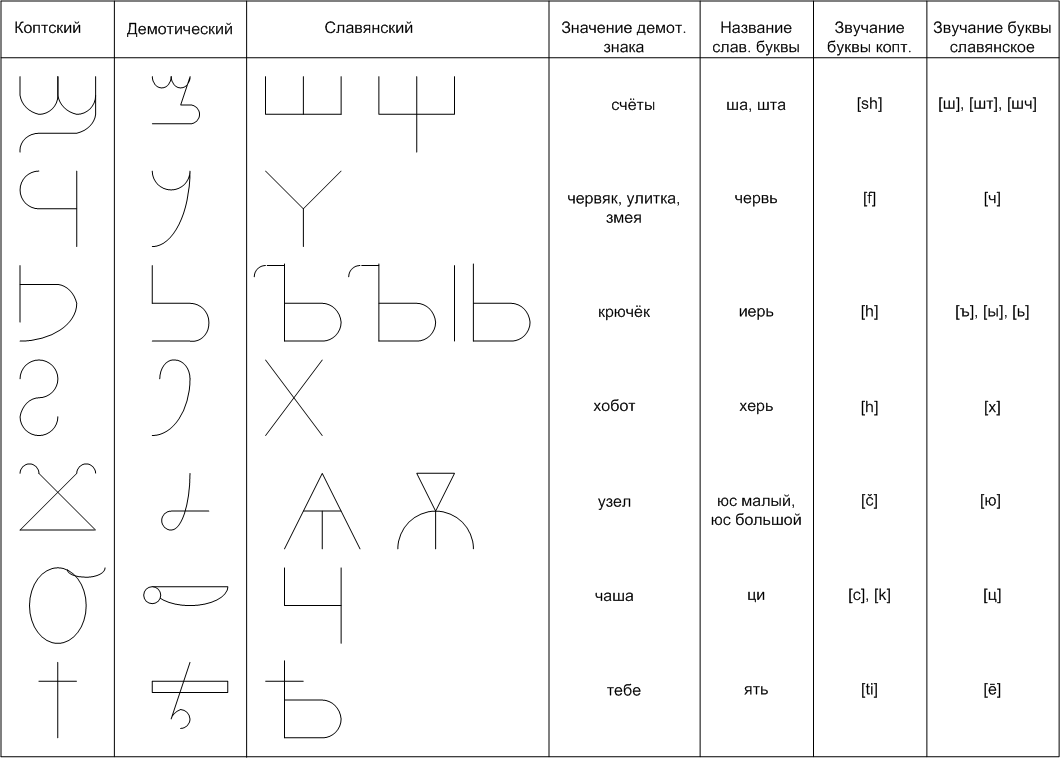
Современное славянское языкознание базируется на ряде мифов, созданных лингвистами и религиозными кругами православной церкви, основанные на следующих постулатах : 1. Русский язык основан на славянской грамоте монахов Кирилла и Мефодия. 2. Слова в письменном языке нельзя преобразовывать в другие слова с помощью законов редукции и замены букв, сходных по начертанию. 3. Нельзя делать инверсию слов. 4. русский язык заимствовал множество иностранных слов, особенно в научной речи. На самом деле, все современные национальные индоевропейские языки созданы именно с помощью редукции и замены букв в слове. Зачастую, изучив один язык, мы горим желанием изучить и другие языки и видим, что слова другого языка часто внешне похожи, за исключением изменения звука слова, изменения приставки и окончания. Изучая иностранный язык, мы как бы закладываем матрицу фонем языка в свою память, аналогичный вычислительной машине. Приступая к изучению нового языка мы опять закладываем новую матрицу в память. Сколько языков, столько и матриц. Чтобы знать сто языков надо иметь в памяти 100 таблиц с десятками тысяч слов. Это, на самом деле так. Но верно и то, что корни слов, как правило, не меняются со временем, а всего лишь обрастают новыми приставками и окончаниями. Поиск и вычленение этих базовых корней может быть произведён с помощью моего метода. В этом случае для изучения 100 языков потребуется знание только 1-й матрицы ключевых корней праязыка. Причём эти корни славянские и по счастливой случайности сохранились в нашей современной речи. История происхождения славянской азбуки похожа на хорошо закрученную детективную историю. Установлению единства взглядов историков по данному вопросу препятствует почти полное отсутствие первоисточников. Единственный дошедший до нас источник – «Сказание о письменах» черноризца Храбра, который рассказывает в своём сочинении, что славяне, будучи язычниками, пользовались греческой и латинской азбукой («письменами»). Там же находим сообщение о создании Константином славянской азбуки в 863 г. Возникает много вопросов : 1. Две азбуки. Почему Константином (Кириллом) и Мефодием было созданы две азбуки – кириллица и глаголица, причём последняя по общему мнению исследователей была создана ранее кириллицы ? Может быть кириллица была создана Кириллом, а Мефодием – глаголица. ? Но утверждается совершенно чётко, что братьями были созданы две азбуки, которые по начертанию букв совершенно различны. Почему были созданы две славянские азбуки с совершенно разными буквами ? Утверждается, что Константин создал глаголицу, а не кириллицу, тогда следует объяснить, почему вторая, а не первая называется кириллицей. В этой связи было высказано предположение, что название «кириллица» раньше принадлежало той славянской азбуке, которую позже стали называть глаголицей. 2. Путаница с именами. В исследовательской литературе упоминаются имена Константина и Мефодия. Так, например описывается проповедничество Константина в Моравии, на Руси, житие Константина, а не Кирилла. В одних текстах упоминается имя Константина, как церковное, а Кирилл – мирское, в других упоминается Константин-Кирилл. В третьих имя Кирилл (до принятия монашества – Константин). Мефодий вообще имеет только одно имя – Мефодий. «Известно, что Мефодий, так же как и Константин, перед смертью принял монашеское имя – Мефодий, тогда как имя данное ему при рождении, не известно» [21] !. Если Константин – монашеское имя, то почему славянская азбука названа по мирскому имени Кирилл ? Почему Мефодий имеет только одно имя ? Из всего комплекса вопросов можно предположить, что Константин и Мефодий создали только одну славянскую азбуку – глаголицу, а другая славянская азбука – кириллица уже давно существовала. Далее, предполагаю, что имя Кирилл является вымышленным или искажённым словом какого-то другого значения. Весь этот клубок вопросов можно распутать, если проследить миссию славянского просветителя по «Житию» Константина. «Из сохранившегося «Жития» Константина известно, что он до Моравской миссии посетил Хозарию (в Приазовье), по дороге туда он остановился в Крыму, в городе Корсуне (Херсонес), греческой колонии на восточнославянской территории. Здесь он нашёл «Корсунские книги», евангелие и псалтырь, на писанные «росьскы письмены», возможно, русскими буквами. Константин якобы встретил даже человека, читавшего эти книги, и сам сразу научился читать их.» [20]. Возвращаясь к полемике, что было изначальней - глаголица или кириллица, читаем : «В кирилловском списке «Книге пророков», переписанном в 1499 г. в Новгороде, приведено послесловие, имеющееся в оригинале, написанным в 1047 г. В послесловии поп Упырь Лихой указывает, что рукопись была написана «ис коуриловице», т. е. с оригинала, написанного другой азбукой. В рукописи встречаются отдельные глаголические буквы. Это даёт возможность считать, что оригинал рукописи был написан глаголицей, которую тогда называли кириллицей («куриловица»)» [20]. Путаница необыкновенная. Из всего выше сказанного, смею предположить, что и «кириллица» и «куриловица» (искажённое слово «корсуница») и «русские письмена» относятся к «Корсунским книгам». «Корсунские книги» – это коптское письмо ! В самом деле, тогда всё встаёт на свои места. Константин и Мефодий действительно создали единственную славянскую азбуку – глаголицу и это ничему не противоречит, а кириллица (искажённое «корсуница») являлась и является поныне коптским алфавитом греческого образца. Глаголица, в славянской письменности со временем потеряло свое значение и в настоящее время существует только в хорватских церковных книгах. Коптский язык представляет важнейшее значение для лингвистов, поскольку является последней ступенью древнеегипетского языка. Коптский язык возник примерно в III веке нашей эры, как средство переводов христианской литературы греков-христиан, проживавших в Египте. На рис. 1. представлен коптский алфавит, который очень похож на славянскую азбуку Кирилла и Мефодия (кириллицу) . И в самом деле, официально считается, что кириллица и коптское письмо написаны на основе греческого (визант.) торжественного унциального письма. Кроме того, коптские буквы, как и буквы кириллицы имеют цыфровое значение. Коптское письмо как и древнеславянское письмо писалось слитно, без разделения слов, знаками пунктуации. Коптский алфавит идеально подходит для произношения славянских фонем. Семь последних идеоматических знаков, которые якобы считают историки, что были включены в алфавит для адаптации к египетской речи, на самом деле эти буквы идеально приспособлены и к славянской речи. Единственное, что могли добавить славянские просветители или их последователи в коптский алфавит, то это это букву SЗ [ДЗ], дифтонги IO [ИО], IA [ИА], IE [ИЕ]. первый идеоматический знак из семи возможно обозначает «счёты или «счёт» - звук [sh], славянское «шть»[Ш], [Щ]. второй идеоматический знак обозначает «червя» или «улитку» или «смею» - звук [š], славянское «червь» [Ч]. третий идеоматический знак обозначает «крючёк» - звук [kr], [kj], славянское «иерь», «иери» [Ъ], [Ы], [Ь]. четвёртый идеоматический знак обозначает «хобот слона» - звук [h], славянское «херь» [Х]. пятый идеоматический знак обозначает «узел» - носовой звук [jo], [jos], [ju], [jus], славянское «юс малый» «юс большой» [Ю]. шестой идеоматический знак обозначает «чашу» - звук [c], славянское «ци» [Ц]. седьмой идеоматический знак обозначает «тебе», т.е. давать что-л. – звук [ti], инверсное славянское «ять». И самое главное, что коптские слова действительно читаются по-славянски (по-русски), т.е. это «русские письмена». И как следствие, можно сказать, что древние египтяне писали по-славянски !
Рис. 1
Рис. 2
На рис. 2. показаны коптские дополнительные знаки, взятые из египетского иероглифического письма в соотношении с буквами славянской азбуки.
Таким образом, кириллица Константина и Мефодия была создана не в IX веке, а в III веке нашей эры на основе коптского алфавита, а ранние тексты коптского письма восходят даже к III веку до нашей эры ! Славяне действительно пользовались, по словам черноризца Храброго, двумя видами письма: греческое (модифицированное коптское письмо) и латинское, которое восходит к этрусскому письму, из которого свормировалась вульгарная латыть, а из последней латинский язык. В обоих направлениях в фонетической составляющей как греческого так и латинского письма сохранились славянские корни, которые можно определить по специальному методу поиска славянских корней в иностранных языках.
Примеры из коптского письма представлены в табл. 1-1 Коптский алфавит представлен в латинской транскрипции.
Таблица 1-1
Структура памяти
Специалисты по искусственному интеллекту (ИИ) и исследователи мозга, образно говоря, «сбились с ног», в поисках отделов памяти, связанных с интеллектуальной деятельностью в области коры головного мозга, но до сих пор нет серьёзного обоснования того, как устроено мышление и речь человека, которые обязательно связаны с памятью. Поэтому в настоящее время возникают универсальные решения и гипотезы по функционированию и структуре мозга. Существует, так называемое понятие «ассиметрии полушарий» мозга, которое заключается в следующем. «Межполушарная асимметрия психических процессов — функциональная специализированность полушарий головного мозга: при осуществлении одних психических функций ведущим является левое полушарие, других — правое. Более чем вековая история анатомических, морфофункциональных, биохимических, нейрофизиологических и психофизиологических исследований асимметрии больших полушарий головного мозга у человека свидетельствует о существовании особого принципа построения и реализации таких важнейших функций мозга, как восприятие, внимание, память, мышление и речь. В настоящее время считается, что левое полушарие у правшей играет преимущественную роль в экспрессивной и импрессивной речи, в чтении, письме, вербальной памяти и вербальном мышлении. Правое же полушарие выступает ведущим для неречевого, например, музыкального слуха, зрительно-пространственной ориентации, невербальной памяти, критичности. В левом полушарии сконцентрированы механизмы абстрактного, а в правом — конкретного образного мышления. Также было показано, что левое полушарие в большей степени ориентировано на прогнозирование будущих состояний, а правое — на взаимодействие с опытом и с актуально протекающими событиями.» [ВП]. «Единая теория, объясняющая с эволюционных позиций многие аспекты межполушарной функциональной асимметрии у животных и человека была предложена В. А. Геодакяном в 1993 г. Согласно теории, латеральная асимметрия возникает в результате асинхронной эволюции полушарий мозга и контролируемых ими сторон тела.» [ВП]. Как было доказано выше асимметрия (перекрёстное управление ОДА ) действительно существует в результате эволюции биосистем, но асимметрия полушарий мозга это совсем другое явление, которое возникло в результате развития речи. Механизмы развития речи требуют формирования областей памяти, которые можно подразделить на следующие: 1. память образов 2. память первофонем 3. память обаяния 4. память осязания 5. память виртуальная образов 6. память преобразования слова 7. память преобразования фонем 8. промежуточная память 9. долговременная память В настоящее время очень популярна гипотеза Карла Прибрама о голографической памяти мозга, которая поддерживается некоторыми ведущими учёными, такими как Стивен Хокинг, Татьяна Черниговская и др. Суть этой гипотезы состоит в том, что память является совокупностью картинок (голографических образов), распределённых по всему мозгу. Эта гипотеза объясняет восстановление памяти при ещё частичной потере, но ведь это можно объяснить и способностью биоклеток к саморегенерации. Относится ли это к нервным клеткам, трудно сказать, но это вполне возможно. «Как заметил П. ван Хирден, если бы мы на протяжении своей жизни каждую секунду запоминали один -бит информации, то для выполнения этой задачи мозг должен был бы каждую секунду совершать около 3 X Ю10 элементарных двоичных операций (нервных импульсов). «Если бы так обстояло дело, то это (прежде всего) было бы невозможно... Однако, столкнувшись с таким парадоксом, постепенно начинаешь понимать... что оптическое хранение информации и ее обработка могут предоставить в наше распоряжение способ осуществить эту «невозможную» операцию... » (1968, р. 28—29).» [20]. Для голографической памяти необходимо голографическое зрение, а нам известно, что зрение у человека стереоскопическое (т.е. это зрение формирует псевдообъёмное изображение). Как с этим быть в гипотезе Прибрама ? Гипотеза Прибрама универсальна для понимания структуры памяти, но именно из-за своей универсальности эта гипотеза не учитывает многие частности и сложности для их воплощения, которые играют важную роль в в чувственно-образном восприятии действительности человеком. «Уиллшоу, Бунеман, Лонге-Хиггинс предложили неголографическую модель ассоциативной памяти мозга (Willshaw, Buneman and Longuet-Hig-' ins, 1969, p. 960). Они также критикуют высказанное мной (van Heer-ец, 1963, p. 393) и Прибрамом (1966, 19696) предположение о том, будто мозг организован по голографическому принципу. Они говорят: «Каким образом мог бы мозг с достаточной точностью подвергать входные сигналы анализу Фурье...» [20]. «В книге, посвященной этой проблеме (van Heerden, 1968), я рассмотрел, каким образом мозг физически мог бы очень хорошо работать в качестве трехмерной голограммы. Если мы имеем трехмерную сеть нейронов, в которой каждый нейрон связан с несколькими соседними, и если нейрон определенного слоя, воспринимая сигнал, будет посылать его нескольким нейронам соседнего слоя, то сигналы в этой сети будут проводиться подобно тому, как волна распространяется в упругой среде.» [20]. Все перечисленные мною памяти могут быть реализованы с помощью механизма деления клетки. Память образов (ПОБ) создаётся на основе ДНК последовательностей нервных клеток по результатам обследования внешних объектов зрительным аппаратом, который формируется у ребёнка с 2-х лет. При совпадении ДНК последовательной образа с двух глаз в памяти формируется единая картинка образа. Память первофонем (ППФ) создаётся на основе ДНК последовательностей нервных клеток по результатам анализа речи. Причём, я предполагаю, что родившийся человек уже имеет некоторые образцы в генетической памяти фонем для возможности сравнения с текущим потоком звуковых сигналов. Память обаяния формирует ДНК последовательности нервных клеток по результатам анализа запахов. Память осязания формирует ДНК последовательности нервных клеток по результатам анализа прикосновений. Память виртуальная образов-фонем (ПВО) формирует ДНК последовательности нервных клеток, сочетая цепочки ДНК образов и первичных фонем в результате повторных опытов. Это очень важная память. Здесь образ сливается со словом, создавая устойчивую связь. Память и механизм преобразования слов (ППС) формирует ДНК последовательности нервных клеток в триплетном коде, преобразуя слова по специальному методу: 1. разделяет сложные слова на составные слова 2. производит инверсию слова (при необходимости) 3. удаляет из слова гласные буквы. 4. производит перемещение (редукцию) согласных букв сходных по звучанию 5. производит перестановку согласных 6. производит подстановку и удаление согласных Память преобразования первофонем (ППФ) формирует ДНК последовательности нервных клеток, сочетая цепочки ДНК памяти образов-фонем и грамматических частиц, префиксов, формирующих производные фонемы необходимые для построения фраз и предложений речи. Иначе память преобразования фонем производит обратное преобразование механизму преобразование слов в фонемы (восстановление слова). Промежуточная память формирует произвольные ДНК последовательности нервных клеток из памяти образов-фонем, формируемые на основе случайных внешних и внутренних событий. Эта память служит буфером при синтезе речи и АДО и в основном функционирует в цикле сна. Долговременная память служит для хранения всех событийных образов в процессе жизнедеятельности человека и используется в процессе воспоминаний. Предположение о существовании памяти фонем возникло у меня в результате поиска корней ностратического языка в различных иностранных языках по определённой методике. Слово характеризуется в основном корнем, а многие корни (и это заметили полиглоты, такие как Петров) в разных языках имеют одну и туже основу на согласных звуках и буквах. Причём, корни состоят в большинстве, как правило, их трёх букв, точно также как и триплет ДНК ! Кроме того, если провести преобразования корня (т.е., например, сделать перемещение согласных) то можно получить другую основу, производную от базового корня. Таким образом, многообразие слов расширяется. Например, русское слово «яблоко» имеет фонему б-л-к > b-l-k, а английское слово apple, означающее «яблоко» имеет фонему p-l > b-l. Это значит, что анализатор речи может распознать слово на 2-х языках. Это всё делается на стадии грамматической обработки фонемы в левом полушарии мозга. «Как предположил Хомски, с мнением которого согласны и крупнейшие специалисты в области молекулярной биологии [53], существуют общие для всех людей (для Homo sapiens как вида) врожденные предпосылки усвоения языка.» [18]. Эти предпосылки как раз и говорят о том, что в памяти человека есть область (память первофонем), которая имеет генетические коды базовых фонем. «Как убедительно показали эксперименты Л. С. Выготского и других психологов, для ранних этапов усвоения языка характерно такое соединение разных значений слова в одном комплексе, следы которого достаточно долго сохраняются и позднее. Особенно отчетливо это явление обнаруживается в младенческом лепете. Отдельные звукосочетания в этом лепете (еще до усвоения родного языка) служат как бы фамильным именем для целого комплекса предметов, соединенных по случайным признакам. Так, годовалый Костя звукосочетанием хь называл горячую кастрюлю, горячую лампу, грелку (хотя бы и пустую) и батарею центрального отопления — даже летом, когда она холодная.» [18]. Это ещё раз подтверждает наличие памяти первофонем. Проговаривание отдельных звукосочетаний является попыткой сравнения текущей фонемы с базовой. «В возрасте «от двух до пяти» дети обучаются языку так, что грамматика родного языка закрепляется в речевом полушарии на всю жизнь. Если в этом возрасте ребенок не получает возможности овладеть речью, он лишается способности говорить.» [18]. Этот метод обучения родному языку состоит в том, что в памяти фонем на месте первофонем появляются фонемы родного языка. Происходит сравнение текущей фонемы с первофонемой параллельно с запоминанием образа предмета и если происходит совпадение звучания фонем, то с повторным сравнением образ-фонема закрепляется в памяти образ-фонема. В противном случае, в отсутствии сравнений механизм сравнения тормозится или совсем останавливается. Это объясняет, что при превышении 5-ти лет ребёнок практически не усваивает человеческую речь. В этом случае возможно создание образа-осязание предмета и развитие навыков мышления, что подтверждается опытами со слепоглухонемыми детьми, которые учились навыкам речи через осязательные жесты. Наличие памяти первофонем объясняет ещё один феномен, который называется «феноменом Мельникова». Русский человек по фамилии Мельников после тяжёлой травмы головы при скоротечном навыке разным иностранным языкам прежде мог практически говорить на 100 с лишним языках и, кроме того, понимал речь на этих языках. Это можно объяснить включением уникального многоканального механизма трансляции первофонем на производные фонемы разных языков. И самое важное, если эти преобразования корней слов можно словесно описать, то можно и написать математический алгоритм процесса преобразования.
Механизм «слово – речь»
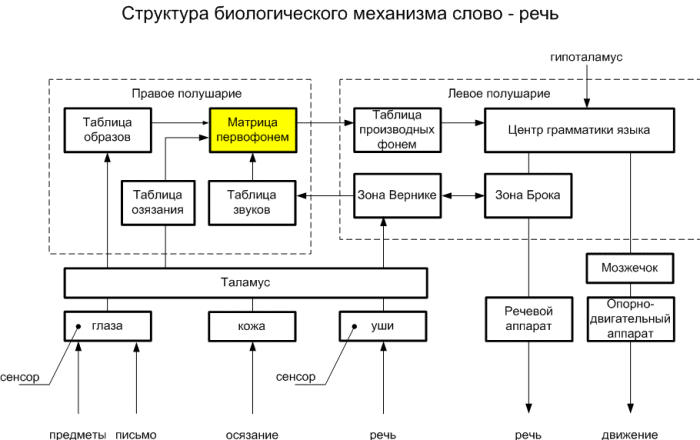
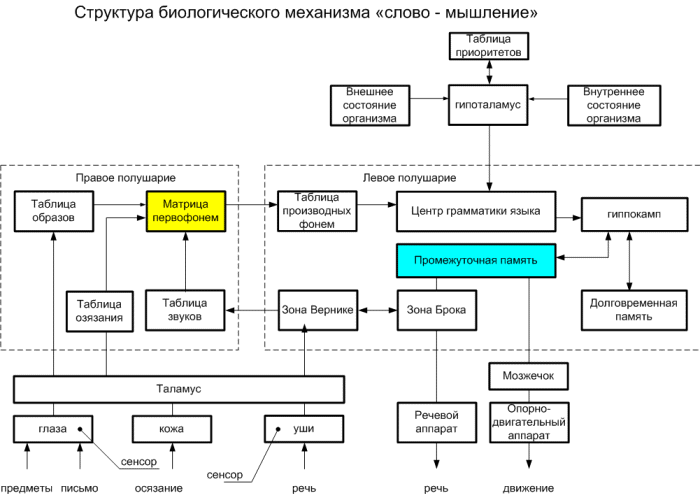
Речь в виде генетического кода, матрицы первофонем хранится в памяти человека. Кольцевая структура первофонем имеет наиболее удобную форму кодирования и хранения информации наподобие машинного кода ЭВМ. При рождении человека матрица первофонем содержится в генетической памяти. С развитием речи ребенка эта матрица как бы пробивается в определенные, конкретные фонемы родного языка. Это похоже на загрузку программного обеспечения (ПО) в вычислительную машину. После загрузки фонем происходит срабатывание механизма слово – речь. Матрица (таблица) фонем начинает из памяти человека (наподобие оперативной памяти ЭВМ) считываться аппаратом речи. Ребенок начинает выговаривать, как бы проговаривать, в виде различных звуков ma-ma (ма-ма), pa-pa (папа), ba-ba (ба-ба), pih-pih (пых-пых), записанные фонемы сначала слогами, затем слитно, по словам. Происходит отладка (в вычислительной технике тоже существует такой термин) механизма речи. Так формируется речь ребенка. Также для формирования речи требуется таблица образов, которая имеет связь с матрицей первофонем и обеспечивает однозначное соответствие между фонемой и образом предмета. Таким образом, для развития речи у ребенка и первобытного человека необходимы, как минимум, следующие составляющие биологического механизма «слово – речь»: 1. таблица образов; 2. таблица звуков; 3. устройство ввода зрительных сигналов; 4. двигательный центр речи; 5. центр понимания речи; 6. таблица преобразования слова; 7. матрица первофонем; 8. таблица преобразования первофонем; 9. арбитр; 10. центр формирования грамматики языка; 11. речевой аппарат; 12. управление опорно-двигательным аппаратом. Таблица образов формируется на этапе обучения речи. Таблица звуков формируется на основе нейронных кодов слов из слуховых сигналов. Устройство ввода зрительных сигналов, слуховых и осязательных сигналов основано на базе таламуса. Двигательный цент речи называется зоной Брокса, который преобразует нейронные коды слов в последовательность артикуляций. Центр понимания речи преобразует слуховые сигналы в нейронные коды слов. Таблица преобразования слов преобразует слова в троичный код первофонем. Матрица первофонем должна находиться в генетической памяти человека. Я полагаю, что у человека должен существовать наследственный генетический код речи, точно также как существует генетический код наследственности. Матрица первофонем (МПФ) состоит из виртуальных связей таблиц образов и звуков. Например, образ человека передаётся в китайском языке иероглифом REN. В МПФ в этом случае формируется связь китайский иероглиф «человек» – REN. Таблица преобразования первофонем преобразует первофонемы в слово и включает различные таблицы корней слова, приставок, суффиксов, окончаний, союзов, предлогов. Арбитр выполняет анализ внутренних и внешних воздействий организма и производит приоритетный выбор действий. Функцию арбитра в человеческом организме выполняет гипоталамус. Центр грамматики языка создаёт синтаксис языка из цепочки слов-образов. Речевой аппарат выполняет артикуляцию звуков речи по командам зоны Брока.. Опорно-двигательный аппарат выполняет команды арбитра на выполнения движений рук и ног. Арбитр – это центральный управляющий орган мозга человека, который называется гипоталамус и выполняет функции контроля внешних и внутренних ситуаций в организме человека и даёт команды на управления опорно-двигательным аппаратом. Управление опорно-двигательным аппаратом выполняет мозжечок. На рис. 3 показана структурная схема механизма слово – речь у человека.
Рис. 3
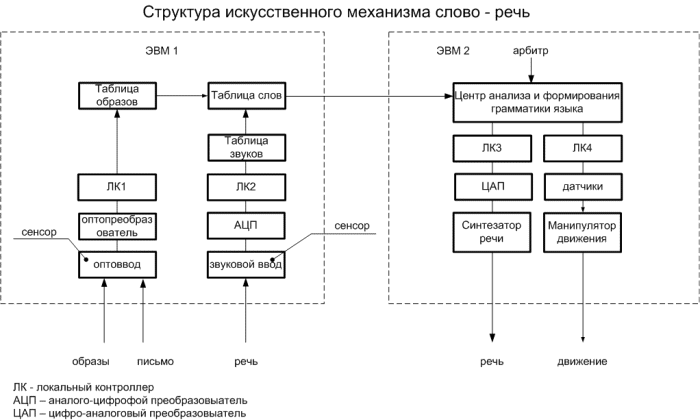
В настоящее время существуют искусственные механизмы слово – речь, например, в робототехнике, которые способны выполнять элементарные речевые команды и вести диалог человек – машина. На Рис. 4 показана структура искусственного механизма слово – речь
Рис. 4
Можно создать полную имитацию искусственного интеллекта, но это всего лишь имитация. Например, робот может выпонять речевые команды, двигать искусственными руками и ногами (манипуляторы), вполне осмысленно отвечать на вопросы, благодаря мощному программному обеспечению. Но простейшее искажения вводного слова может поставить робота в тупик. Например, вместо слова «яблоко» (рус). или apple (анг.) можно сказать или написать в тексте блк или plc. Команда не выполнится. Филолог М. А. Кронгауз в своей лекции по лингвистике (tvkultura.ru) сказал замечательные слова, о том что слово опознается по ключевым буквам ! Ключевые буквы – это и есть первофонемы, которые хранятся в матрице первоформ мозга человека. Только человек может опознать искаженные слова и причем довольно легко. Из этого следуют выводы: 1. Искусственный механизх слово – речь неспособен опознавать искаженные слова, а человек может благодаря гену речи. Для распознавания искаженных слов должно быть создано программное обеспечение, которое будет перебирать тысячи комбинаций для понимания одного слова и миллиарды – для всего словарного запаса языка, что может превратить оперативную память искусственного интеллекта в монстра огромного объема. 2. Двухязычная или многоязычная речь человека возможна только благодаря матрице первофонем, которая способна распознавать слова из разных языков.
Механизм «слово – мышление»Последним и наиболее важным этапом в развитии речи человека является создание механизма «слово – мышление». Над этой проблемой десятки лет бьются ученые всего мира и до сих пор она не решена. Понимаие этого механизма создаст реальные предпосылки для создания искусственного интеллекта. Попробуем представть гипотезу, которая поможет разрешить эти проблемы. На наш взгляд, механиз «слово – мышление» основан на формирования временной и промежуточной памяти, наподобии кэш-памяти в ЭВМ. Эта промежуточная память в противовес долговременной памяти является хранилищем кратковременной информации, поступающей извне в мозг человека. Эта временная память постоянно и непрерывно сканируется арбитром. Эта память входит в состав механизма сна. Эсли бы не было этой промежуточной памяти, то мозг человека был перегружен информацией и практически не смог бы существовать долго, поскольку информация поступает извне непрерывно. Примером отсутствия промежуточной памяти у человека являются люди с феноменальной памятью. Они способны запоминать и воспроизводить через речь огромные тексты. Но эти люди в умственном развитии находятся на уровне ребенка. В промежуточной памяти анализируется и отсеивается ненужная и лишняя информация, а необходимя информация поступает в долговременную память. При необходимости данные из долговременной памяти поступают во временную память по команде арбитра. Принцип селективности и избирательности промежуточной памяти является основным в механизме «слово – мышление». На Рис. 5 представлена схема биологического механизма «слово – мышление».
Рис. 5
На Рис. 6 представлена предполагаемая схема искусственного механизма «слово – мышление».
Рис. 6
Легкое дыханиеМногие выводы, сделанные исследователем П.П Горяевым практически совпадают с материалом данной статьи по происхождению языка и речи. И хотя эксперименты проводимые П.П Горяевым считаются антинаучными в академической среде, можно опереться на эти данные, поскольку даже в шутке есть доля истины.
«Выяснилось, что ДНК и человеческая речь (тексты) обладают стратегически близкой фрактальной структурой в геометрическом смысле.» [20].
«Хомский, вероятно, прав в том, что глубинные синтаксические конструкции, составляющие основу языка, передаются по наследству от поколения к поколению, обеспечивая каждому индивидууму возможность овладеть языком своих предков. То, что ребенок легко учится любому языку, объясняется как раз тем, что в своей основе грамматики всех языков совпадают.» [20].
«Вероятно, процесс естественной эволюции абиогенно возникшего “первичного бульона” из органических молекул - предшественников РНК, ДНК, белков и других существенных компонентов биосистем был сочетан с актом введения экзобиологической информации в первые нуклеиновые кислоты, она была артефактом. И эта информация была рече-подобной. “В начале было слово...”. И эти слова были фрактальны, условно начиная с дуплетно-триплетного кода ДНК-РНК, на первых этапах являющегося простейшим языком с четырех буквенной азбукой.» [20].
Анализ сравнительного словаря В.М. Иллича-Свитыча показывает, что праславянские корни присутствуют во всех базовых структурах ностратических языков. Основу праславянских корней составляют кольцевые структуры с начальным и конечным H. Можно предположить, что придыхательный звук HaH был первым звуком в речи первобытного человека. «В начале было Слово» и это слово (вздох, выдох HaH) как легкое дыхание распространилось по всему миру. «И создал Господь Бог человека из праха земного, и вдунул в лице его дыхание жизни, и стал человек душею живою» [Библия, Бытие, 2.7.]. Фонема HaH (fonema > zvuchanie –звучание (праслав.)(пропуск z, редукция v/f, замена ni/m)) – это естественное дыхание человека. Вдох (H)aH, выдох – Ha(H). Кольцевые структуры речи на основе HaH похожи на молекулы ДНК, РНК, генетический код речи формируют многообразие звуковых цепочек HxH, которые создают фонемы: HaH, HbH, HcH, HdH, HeH, HvH, HjH, HkH, HnH, HmH, HoH, HpH, HrH, HsH, HtH, HuH. Первоначальные фонемы не содержали звук R, как наиболее сложный звук человеческой речи, требующий реверберации кончика языка в полости рта. Что мы и видим на примере формирования речи у ребенка, издающего первые звуки. Звук R может и не развиться, и таким образом сохраняется в речи взрослого человека, как дефект речи, который называется картавостью или грассированием. Поэтому переход звука L/R, (фонемы HlH, HrH) является наиболее частым видом редукции в письменном языке. При развитии речи первобытного человека начальный и конечный H стал трансформироваться в согласный звук K, который стал переходить в звук G. На основе редукции H/K/G первофонемы получили свое развитие в формировании цепочек KxK, KxH, HxK, GxH, Hxg, GxG. Редукция здесь не соответствует понятию редукции в языкознании, как ослабление звучания гласных в безударном положении. редукция - reduction - pere-dviganie - передвигание (слав.)(пропуск p, замена v/u), иначе "редукция" в истинном смысле есть "передвижение согласных". Характерно, что кольцевая структура первофонем позволяет читать фонему как слева-направо, так и справа-налево. В результате чего возникает замечательная возможность формирования инверсных фонем. Инверсия фонемы во многом определило различие языков. Но именно в славянских языках сохранились производные слова от инверсных фонем. Так, например gl – глотать, но lk – лакать. Инверсные фонемы попали в другие ностратические языки в качестве новых словообразований. Губные смычковые звуки В, Р тоже произносятся довольно легко, не требуя усилий. Поэтому на основе их сформировался второй ряд первофонем в сочетании Bh, Ph. Звук H в дальнейшем отпал, но сохранился в первозданном виде в индоевропейских языках, например, ĥnebh – пуп, ĝhelhu – гладкий. Таким образом вариантность перфофонем значительно увеличилась: BxH, HxB, PxH, HxP. Третим этапом развития первофонем стало формирование аффикса в составе фонемы, например, HrxH, HxrH, HlxH, HxlH. На базе третьей формы первофонем существует множество производных слов в различных языках. Таким образом, мы проследили всю цепочку формирования и развития первофонем от HaH до, HxH, от HxH до HxxH, xHxH, HxHx, накоторых строятся практически все слова из всего многообразия человеческих языков. Четвертым этапом развитие речи стало формирование приставок, суффиксов и окончаний. В окончательном варианте слово выглядит так: приставка – первофонема – суффикс - окончание. Примечательно то, что слова праславянского языка, такие как con – «конец», zad (инверсное dis, de[s]) – «зад» вошли в состав латинского языка в качестве составного слова. Пятым, окончательным этапом развития речи стало формирование предложения, куда вошли местоимение, предлог, подлежащее, сказуемое, наречие, деепричастие. Принцип инверсии фонемы сохранился в русском языке не только на уровне слов (см. список антонимов русского языка в разделе «Антропогенез»), но и в синтаксисе русского языка. Слова в русском языке можно ставить в любом порядке предложения независимо от функции., например: «Я тебя люблю» «Тебя люблю я» «Люблю я тебя». И эта инверсия существует только в синтаксисе славянских языков ! Это является еще одним важнейшим аргументом первородности праславянского языка. Таким образом, признаком первородности языка является: 1. инверсия фонем; 2. инверсия слова; 3. инверсный синтаксис предложения. Слово «конец» kon является и началом в инверсном чтении kon > nach – начало. В этом заключается удивительный, почти метафизический смысл русского слова. Все в природе мира имеет свое начало и конец, но конец, в тоже время является «началом» нового, а новое всегда является началом «конца». Это бесконечное состояние существует во всем материальном мире, в законе сохранения энергии, в рождении и отмирании биологических клеток, рождении и умирании человека, в рождении и угасании звезд Вселенной. Кольцо является символом мироздания, поскольку только кольцо бесконечно, оно не имеет ни начала, ни конца. В русском языке слово «кольцо» среднего рода, ОНО обезличено, ОНО не принадлежит никакому роду, ОНО нечто среднее между началом и концом.
По образцу и подобию
В предыдущем разделе мы выяснили, слова (информационный массив, матрица) в памяти человека удобнее хранить в коде. И наиболее удобный 3-х битный код, как код ДНК структуры в таблице первофонем. Формирование кода таблицы первофонем требует преобразования слова (таблицы преобразования). Например, слово "сосуд" - vessel (англ.) преобразуется: vessel > vssl (выделение согласных букв) > vlss (перестрановка ss/l) > vlg - влага (слав.)(редукция g/s). Пример создания первофонем слова "сосуд". сосуд (изображение сосуда) - ib (др.-егип.) > cub - кубок (слав.) > cb (фонема) сосуд - ssd > sudn - судно (слав.) > srd - сердце/середина (слав.) > sd (фонема) сосуд - vas (лат.) > vlag - влага (слав.) > vlg (фонема) сосуд - urna (лат.) > vlajnaj - влажный (слав.)(замена v/u, редукция l/r) > vlg (фонема) сосуд - pultarius (лат.) > bul-tara-us - буль-тара (слав.) > bl (фонема) сосуд - skevos (греч.) > vlgj-os > vlaga - влага (слав.)(инверсия skev, редукция g/k, j/s, пропуск l) > vlg (фонема) сосуд - aimofora (греч.) > paimoj-vlaga -поимая влага (слав.) > pm (фонема), vlg (фонема) сосуд - doxeio (греч.) > vodio - вода (слав.)(инв. dox, замена v/x) > vd (фонема) сосуд -aggeio (греч.) > vlagga - влага (слав.)(пропуск vl) > vlg (фонема) сосуд - vessel (англ.) > vlgg - влага (слав.)(перест. ss/l, редукция g/s) > vlg (фонема) сосуд - Gefäβ (нем.) > vlga - влага (слав.)(перест. G/f, редукция v/f, пропуск l) > vlg (фонема) сосуд - cup(bi) (турк.) > cubbok - кубок (слав.)( редукция b/p, пропуск k) сосуд - astia (фин.) > vadia - вода (слав.)(пропуск v) > vd (фонема) сосуд - suon (фин.) > sudn - судно (замена d/o) >sd (фонема) Таким образом, таблица фонем слова "сосуд" из разных языков включает фонемы: [cb, sd, vlg, vd]. Каким образом была создана таблица первофонем ? Примеры полиглотизма навевают мысль, что таблица первофонем могла бы формироваться на основе заимствования информации полиглотом из информационного поля, например, неосферы, от иноземного разума, от коллективного разума и других фантастических областей разума. Но это всё домыслы уфологов и фантастов. На самом деле всё гораздо проще. Таблица первофонем формировалась в памяти человека на протяжении тысячелетий при общении, ассимиляции различных народов, этносов и рас. Год за годом, век за веком формировалась эта ТПФ. Вольтер говорил, что человек родится совершенным и, видимо, потому, что в его генетическом коде заложена база с огромным потенциалом памяти и образов. Но эта ТПФ весьма кратковременна для воспроизведения в процессе обучения человека. Наиболее оптимальным в развитии человеческих способностей является младенческий и ранний подростковый возраст от 1 до 5 лет. В это время ребёнок имеет огромные способности для изучения языков. Примером тому является ранее существовавший в 19 веке в Европе, в том числе и в России институт гувернёров и гувернанток в дворянских и купеческих семьях, благодаря которому, ребёнок мог изучить до 5-ти языков, а с учётом гимназического курса латинского и греческого языков - до 7 языков в свободном владении. В настоящее время Белла Девяткина девочка 4-х лет на ток-шоу "Удивительные люди" демонстрировала знание пяти языков в понимании и разговоре. И это вызвало бурю восторгов, хотя в этом нет ничего необыкновенного. В 1,5-2 года дети уже понимают слова благодаря ТПФ. Но почему же в наше время не используется опыт института гувернёров ? И почему в общеобразовательных школах (я имею в виду Россию), начиная только с 5-го класса детей начинают учить 1-му иностранному языку, хотя возможно изучать несколько языков одновременно в дошкольном возрасте. Затем в техникумах и вузах учат другому языку, в результате чего ни тот ни другой язык, учащие его, не знают должным образом. Может быть существуют какие-то ограничения на детскую гениальность ? Рассмотрим ряд феноменов, связанных с полиглотизмом.
Дети-Маугли
Хорошо известен такой феномен как дети-Маугли. Если не срабатывает механизм преобразования слов в первофонемы по причине того, что в память ППС поступают звуки нечеловеческой речи (животного), которые не совпадают с кодами матрицы первофонем или отмирают клетки матрицы первофонем, то механизм «слово – речь» не срабатывает. В этом случае ребенок даже в подростковом возрасте не способен понимать человеческую речь и не способен говорить на человеческом языке. Это дети – Маугли (о которых мы уже писали в разделе «Антропология»). Блокировка механизма ППС, очевидно, связана с возрастом человека. Механизмы ППС и ППФ работают в младенческом и раннем подростковом возрасте (1-5 лет), затем они блокируются, как показывают опыты с детьми-Маугли. Есть еще одна избитая истина, что устами младенца глаголет истина. Это говорит о том, что дети до определённого возраста гениальны. Представьте себе, что эта гениальность сохраняется у детей старшего возраста, в отрочестве, молодости и так до старости. Люди всех возрастов будут гениальными, все будут говорить на 100 и более языков, генерировать идеи, которые так осчастливят человечество, что мы будем жить при коммунизме и всеобщем благосостоянии. Но природа мудра и дала людям разные возможности и таланты, благодаря конечному сроку действия механизма ППФ, хотя все с рождения гениальны. Вероятно так сложилось и потому, что механизм ППФ работал активно на стадии формирования языков у древнего человека в течении многих тысячелетий, а ребёнок 2-5 лет проходит эту стадию за 3 года, также как и формирование речи за тоже время. Сто мудрецов (и даже два) не смогут ужиться в одном доме. Природа сделала так, что человек вынужден трудиться в поте лица, добывая средства к существованию, и только единицы способны нести гениальность. Так было с Ньютоном, Эйнштейном и др. гениями. Но есть другой феномен, который раскрывает многоязыковый талант человека уже в зрелом возрасте.
Феномен Вилли Мельникова
Итак, мы определили для себя, что золотой ключик, который вставляется в дверь комнаты талантов и изобретательности захлопывается в раннем подростковом возрасте. Тем не менее, полиглотом можно стать на примере А. Петрова, но как при этом работает матрица первофонем ? Она никак не работает. Просто изучение языков происходит по многочисленным методикам, но они не используют МПФ, а формируют новые таблицы памяти в мозгу человека, которые виртуально связываются с таблицей образов. Поэтому все эти методики связаны с элементарной зубрёжкой или заучиванием слов в отличие от детей-вундеркиндов, которые осваивают языки как бы играючи благодаря тому, что работают с МПФ, ППС и ППФ. " …усвоение значений слов оказывается процессом чрезвычайной длительности, в какой-то степени не прерывающимся на протяжении всей жизни человека. " [18]. О включении МПФ в процесс обучения языкам у детей говорит следующее высказывание В.В. Иванова : " Как убедительно показали эксперименты Л. С. Выготского и других психологов, для ранних этапов усвоения языка характерно такое соединение разных значений слова в одном комплексе, следы которого достаточно долго сохраняются и позднее." [18] Однако есть ещё феномен Вили Мельникова, который состоит в том, что в результате травмы головы и контузии, которые получил В. Мельников во время афганской войны, он неожиданно для себя и окружающих заговорил на 100 языках. Эти сто языков включают по собственным словам полиглота: британский английский, американский английский, канадский английский, австралийский английский, креольский английский, итальянский, испанский, французский, немецкий и его диалекты, албанский, венгерский, чешский, белорусский, датский, фарерский, шведский, исландский, фризский, древнеанглийский, финский, латышский, вестготский, гаэльский, шэттли, дари, пушту, къялиуш, санскрит, бенгшали, синдхи, мохенджо-даро, малаялам, джанти, непали, тибетский, тангут, чжурчжень, нганасон, аркаим, Орхон, серкул, шумеро-аккадский, Угарит, арамейский, набати, древнеегипетский, туарег-фитинак, суахили, эве, догон, мэо, японский, ительменский, алюторский, старославянский (киррилица и глаголица), хеттский, наси-доньба, айнский, юкагир, цыганско-кэлдэрарский, къярдилд, калкадун, гавайский, нан-мадол, икшью, древнеирландский огам, хопи, навахо, кечуарани, гуанчи, пиктский, тольтек-науатль, эйемпу, уавниффа, кохау-ронго-ронго, кхаршат, цклан, си-по, фракийский, словенский, шоштхвуаЮ шайен, согдийский, дхур-вуэммт, пхадмэ, якутский, чибча-артамбо, ваи, чероки, чькуатта, маурья, фьярр-кием, хакутури, рохгау, хекагауайчиунэ, рдеогг-семфанг, юпик, кри. Феномен Мельникова вызывает интерес у лингвистов и психофизиологов. Некоторые цитаты учёных приведены ниже:
"Мы изучали способности Вилли. Он, безусловно, гениальный человек./…/ Он был стандартным полиглотом до травмы./…/ Благодаря Вилли мы, кстати, нашли общее в судьбах полиглотов. Во-первых, любовь к языкам у них рождается в детстве. Во-вторых, растут они, как правило, в многоязыковой семье или среде. То есть с ранних лет для них мир звучит на разных языках. И главное — цель, которую они себе ставят." Об этом пишет доктор филологических наук, ведущий научный сотрудник Институт языкознания РАН, профессор Государственного лингвистического университета Дина Никуличева. Феномен В. Мельникова при ближайшем рассмотрении не столь уж уникален, если рассматривать его в аспекте раннего изучения языков у детей, а скорее связан с особенным стечением обстоятельств. Судя по биографии, В. Мельников начал изучать языки в 4-5 лет и к шестому классу изучил некоторые германские языки, а также древние рунические типы письменности, отсюда и его знание немецкого языка и его диалектов, а также древних рун. В ветеринарной академии он с помощью однокурсников-иностранцев изучал ряд африканских и южноамериканских языков. В Афганистане он ознакомился с местными афганскими языками и диалектами. В 90-е годы, по собственным заявлениям, освоил множество языков благодаря личным контактам с их носителями. В. Токарев не просто изучал языки, но он и контактировал с иностранцами, то есть находился в среде, способствующей скорейшему усвоению чужого языка. Известно, что можно долго и упорно изучать язык, но не освоив разговорные навыки в чужой среде, язык быстро забывается или осваивается с великим трудом. Несомненно, у В. Мельникова были по природе или выработались в процессе изучения способности к освоению чужого языка на слух, подобно тому, как попугай осваивает множество человеческих слов и даже осознанно их применяет. Критика знаний иностранных языков у В. Мельникова весьма основательна. " Возможности и знания В. Мельникова не имели объективных подтверждений. В его записях на разных языках содержатся ошибки, а некоторые записи представляют собой скопированные с ошибками цитаты из различных книг, отдельные предложения лишены смысла. Некоторые из языков, на знание которых претендовал В. Мельников, на самом деле являются либо диалектами (как американский английский или френглиш), либо разнородными языковыми группами (креольские языки). Звучание некоторых из языков, на владение которыми претендует В. Мельников, до сих пор не расшифровано (например, ронго-ронго, язык цивилизации долины Инда), некоторые из называемых языков не существуют вовсе (такие, как «шумеро-аккадский» или «дхурр-вуэммт»). Также в ряд известных ему «языков» он включал названия письменностей (руническое письмо, глаголицу)." [ВП]. Для меня важно то, что В. Мельников, по всей видимости, не использовал МПФ, даже если предположить, что после травмы у него открылся механизм ППС и ППФ. Иначе, он мог бы знать все так называемые "мёртвые языки", а не только фракийский или шумеро-аккадский, например, такие как этрусский, иллирийский, малоазийские языки, хотя упоминается хеттский. Удивляет знание древнеегипетского языка, транскрипция слов которого практически не читается, а известен только смысл слов. На мой взгляд, древнеегипетский письменный язык, который известен в современной египтологии благодаря открытию Шампольона, является вообще искусственным языков. Тогда В. Мельников должен знать и коптский язык, но он не упоминается. В списке языков В. Мельникова вообще не упоминается латинский и греческий языки, на основе которых формируются множество современных научных терминов. Удивляет также знание российским полиглотом японского языка, но не говорится о китайском языке, который является основой японского и корейского иероглифического языка. И что именно знал В. Мельников в японском языке, иероглифы или их перевод ? Неизвестно. Но известно то, что многие японские слова имеют славянское происхождение. Об этом писал российский филолог А.Н. Драгункин в своей книге "Происхождение японского языка". Например: abaraya (япон.) > xibaraja > хибара (слав.)(пропуск x) aria (япон.) > burnia > бурный (слав.)( пропуск b) ashi (япон.) > peshij - пеший (слав.)( пропуск p) ato (япон.) > zado - зад (слав.)( пропуск z, редукция d/t) eki (япон.) > reka - река (слав.)( пропуск r) ido - колодец (япон.) > pit - пить (слав.)( пропуск p, редукция t/d)/pit - яма, впадина (англ.) oku (япон.) > bok - бок (слав.)( пропуск b) omou (япон.) > duma - дума (слав.)( пропуск d) osa(ge) (япон.) > kosa - коса (слав.)( пропуск k) uchi (япон.) > xata/chum - хата/чум (слав.)( пропуск x, замена t/ch; инверсия uch, пропуск m) urushi (япон.) > varnish - лак, блеск (англ.)/volnistj - волнистый (слав.) uso (япон.) > log - лож (слав.)( пропуск l, редукция g/s) utau (япон.) > vitau - выть (слав.)(замена v/u) utsu (япон.) > bitsu - бить (слав.)( пропуск b)
Мои находки в японском: tanaku - золото (япон.) > dengi - деньги (слав.)(редукция d/t, g/k) darima - кукла, даримая на Новый год (япон.) > darimaj - даримая (слав.), аналог матрёшки/doll - кукла (англ.)( редукция l/r). bazuka - противотанковое ружьё (япон.) > pushuka - пушка (слав.)( редукция p/b, sh/z) samuraj - воин (япон.) > samj-mujaj - самый мужний (слав.)(удвоение m, замена j/r) harakiri - самоубийство самурая (япон.) > chrevo-koli - чрево коли (слав.)( редукция ch/h, пропуск v) > kill - убивать (англ.)/kolot - колоть (слав.)
Можно сделать вывод, что В. Мельников хорошо знал или легко осваивал те современные и древние уникальные языки, которые по корневому составу были близки славянскому языку, например, старославянский белорусский, чешский, фракийский, хеттский, шумерско-аккадский (?), японский. Это подтверждает тот факт, что МПФ была основана на славянских ностратических корнях, которые являлись первоосновой для всех мировых языков. Что касается шумеро-аккадского языка, существование которого отрицает лингвистическая наука, хотя трудно отрицать наличие шумерского словаря на основе шумерских литературных текстов с порядком примерно 3000 слов.
Известный российский историк В.Н. Татищев, который написал историю государства российского с древнейших времён, так писал о древности славянского письма.
"О ДРЕВНОСТИ ПИСЬМА СЛАВЯН
Первое, что к повествованиям относится, есть письмо, ибо без того ничего на долгое время сохранить невозможно, и хотя устные предания через память долго сохранены быть могут, но не все цело, так как память не всех людей так тверда, чтоб слышанное единожды или дважды правильно и порядочно без ущерба или прибавки пересказать; следственно все деяния тогда, которые записать удалось, гораздо правдивее чрез роды переданных. Когда же, кем и которые буквы первее изобретены, о том между учеными распря неоконченная. Прежде букв употребляли иероглифию, или образами описание, и того мы касаться не будем. 2) Иностранных басня. Треер. Что же всеобщего славянского языка и собственно славяно-руссов письма касается, то многие иноземцы от неведения пишут, якобы славяне поздно и не все, но один от другого письмо получали, и якобы руссы до пятнадцатого века после Христа никаких историй не писали, о чем Треер из других в его Введении в русскую историю 23, стр. 14, написал, как и профессор Байер погрешил, гл. 17, н. 61. Другие того дивнее, что рассказывают, якобы в Руси до Владимира никакого письма не имели, следственно древних дел писать не могли, обосновывая это тем, что Нестор более 150 лет после Владимира писал, но никоего прежнего писателя истории не воспоминает. Впрочем, это мнение, думается, от таких произошло, которые не только других древних славянских и русских историй в Руси, но даже оную Несторову никогда видели или читая понять и рассудить не могли, как, видимо, и преславный писатель Байер, который хотя в древностях иностранных весьма был сведущим, но в русских много погрешал, как в гл. 16, 17 и 32 показано. Подлинно же славяне задолго до Христа и славяно-руссы собственно до Владимира письмо имели, в чем нам многие древние писатели свидетельствуют и, во-первых, то, что вообще о всех славянах рассказывается. 3) В Колхисе. В Европе. Ниже из Диодора Сицилийского и других древних будет вполне очевидно, что славяне сначала жили в Сирии и Финикии, гл. 33, 34, где по соседству еврейское, египетское или халдейское письмо иметь свободно могли. Перешедши оттуда, обитали при Черном море в Колхиде и Пафлагонии, а оттуда во время Троянской войны с именем генеты, галлы и мешины, по сказанию Гомера, в Европу перешли и берегом моря Средиземного до Италии овладели, Венецию построили и пр., как древние многие, особенно Стрыковский, 24 Бельский 25 и другие, рассказывают. Следственно, в такой близости и сообществе с греками и итальянцами обитав, несомненно письмо от них иметь и употреблять способ непрекословно имели, хотя это только по мнению моему." [21]. Славяне, проживавшие в Сирии и Финики, назывались пеласгами. Пеласги освоили всё Средиземноморье. О пеласгах собран обширный материал в моей статье "Пеласги и древнее письмо" [22].
Интересно, что другой известный российский полиглот Наташа Бекетова знала японский язык из 120 языков, о которых она заявляла.
Феномен Наташи Бекетовой
О феномене Наташи Бекетовой стало известно в 2003 году, когда на уроке математике на неё накричала учительница и ученица потеряла сознание. После обморока она вдруг проявила способности говорить, по её собственным словам, на 120 языках, которые включают: древнекитайский, древнеанглийский, монгольский, древнеяпонский, арабский, французский, латынь, итальянский эпохи Возрождения, тангутский, этрусский, вьетнамский, корейский, испанский, суахили, фарси, корейский 6 века и др. Н. Бекетова говорила на "мёртвых" языках народов, которых уже нет: суаму, хокко, уавуалу, нгоба и др. Самое интересное, что Н. Бекетова связывает языки с её прошлыми жизнями и рассказывает что-то о своей жизни в первобытном племени, в средневековой Японии, в Англии 17 века и во Франции в качестве наполеоновского солдата, погибшего от удара штыком. В предпоследней жизни Наташа, по её словам, умерла в 1920 году в Германии от тифа, а в нынешней жизни стала продавщицей. Критика знаний иностранных языков у Н. Бекетовой тоже основательная. Психолог высшей категории Александр Боршняков утверждает, что Н. Бекетова прекрасно говорит на японском языке, что подтвердила преподаватель по японскому языку Краснодарского госуниверситета Миюки Такаги. Также полиглот показала знания французского, но, вот, тестирования по арабскому, турецкому и корейскому она не выдержала. Проверяли Н. Бекетову и на знание древних языков: надпись на Фестском диске (крито-микенское письмо), надпись на этрусском на кинжале, 14 надписей на печатях и бронзовых пластинах, написанные на диалекте государство Млехха (р. Инд XXX-XX вв. до н.э.), алекановская надпись (археолог Городцов, X век, под Рязанью), надпись на кривянской баклажке (Смоленская губерния IX век). По первой надписи (фестский диск) Наташа сначала бегло прочитала его по-праславянски, затем сделала перевод на русский язык. Ю.Г. Янкин сравнили его с переводом профессора Гриневича. Выявилось явное совпадение общего содержание надписи. Дальше не имеет смысла цитировать протокол испытаний. Так называемый профессор Гриневич является автором метода чтения этрусского письма, который состоит в разбиении этрусских слов на буквы, а затем по некой таблице эти буквы превращались в слоги, складывающиеся в праславянские слова. Можно представить, что из этого получается. И перевод Н. Бекетовой почти совпал с этой абракадаброй. "В результате проведённых испытаний была подтверждена способность Бекетовой читать и понимать праславянские тексты различных диалектов (этрусского, крито-микенского, индского). Эксперт считает, что испытуемая обладает генной памятью, то есть памятью своих древних предков, владевших письменностью на различных языках. Подписи Ю. Янкин и А. Кибкало. 2001 г." [http://www.kp.ru/daily/23021/3332/ ] Следует отметить, что ни Ю. Янкин, ни А. Кибкало не являются экспертами по сравнительному языкознанию, а сравнение переводов полиглота Н. Бекетовой с переводами Гриневича является вопиющим антинаучным явлением. "...Ни вор, поработивший меня... Ни казни, ни мучай, ни трать сил на того врага, чтобы он не порабощал тебя в дальнейшем " (из протокола испытаний надписи на фестском диске). Надпись на фестском диске, написанная крито-микенским письмом, а точнее знаками наподобие рисуночных иероглифов до сих пор не дешифрована. Я допускаю, что Н. Бекетова могла знать разные варианты алфавитного письма, но знание иероглифов маловероятно. Вопрос в другом, Н. Бекетова, рассказывая о своём прошлом, претендует на реинкарнацию, а это может быть связано со словами-образами, которые хранятся в памяти человека.
Синдром полиглота
У исследователей имеется немало примеров о синдроме полиглота (считается не менее 2 тысяч). Доктор психологических наук Кембриджского университета Софи СКОТТ так пишет о синдроме полиглота: "Все изученные мной жертвы «синдрома полиглота» перенесли инсульт в левой части мозга. Главные причины синдрома - травмы, инсульт, атрофия нервных клеток. При поражении мозга старая, заложенная еще в детстве информация нарушается в меньшей степени, чем та, что усваивается позже. Поэтому при сбое новая информация быстро стирается, а наружу выскакивает хорошо позабытое старое" [http://www.kp.ru/daily/23021/3332]. Можно предположить, что обморок Н. Бекетовой и травма головы В. Мельникова были связаны с левой половиной полушария мозга, что послужило катализатором включения механизма преобразования первофонем в слово (ППФ). Именно это могло послужить появлению из глубинной памяти слов-образов, связанных с древнейшими и уже давно забытыми языками, слова-образы, в свою очередь, побудили отрывочные фантазии-воспоминания о, якобы прошлой жизни.
Выводы по механизмам мышления
Все мои исследования в области сравнительного языкознания направлены на реализацию метода поиска славянских корней в иностранных словах [23]. На сколько удачен этот метод, не мне судить, но надеюсь, что материалы данной статьи пригодятся исследователям в области искусственного интеллекта и комплексного изучения языков.
Левша
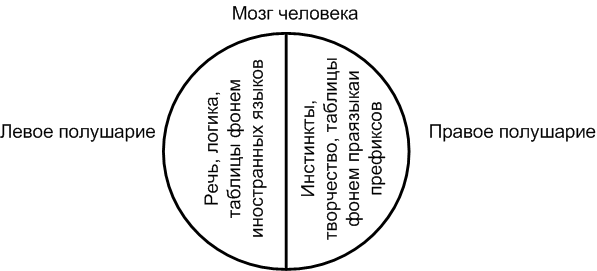
Многим известен сказ о том, как русский ремесленник Левша блоху подковал в английском королевстве. Но почему ремесленник прозван Левшой ? В русском языке есть выражение «Ум за разум зашел». Есть ли нечто общее в имени Левши и выражении. Оказывается есть. Для этого мы обратимся к развивающейся ныне науке нейрологии, изучающей функции мозга и в частности речь. Всемирно известный лингвист В.В. Иванов, помимо письма этрусков и хеттов занимается изучением особенностями речи в структуре мозга. И вот, что он обнаружил совместно с медицинскими специалистами. Оказывается, левая половина мозга человека отвечает за речь и логические операции, а правая за развитие творческих процессов, включающих живопись, музыку, искусство. Но в отдельных случаях правая половина мозга может принять на себя и речевые функции. Это происходит в том случае, если речь человека двуязычна, то есть, если он знает не менее двух языков. Причем функция речи в правосторонней половине мозга отвечает за первородный язык, а левая половина мозга за приобретенный язык. Написание текста правой рукой связано физиологически с левым полушарием переднего мозга человека. Можно предположить, что письмо левой рукой связано с правым полушарием. Каким образом речь связана с письмом ? При письме человек мысленно произносит буквы, причем это происходит чисто автоматически, которые фиксируются в нервных клетках полушарий как речевые импульсы. Сохранение родового разговорного языка в правом полушарии на уровне подсознания подтверждает древний процесс письма левой рукой с направлением письма справа - налево. Следовательно, написание левой рукой является наиболее древним способом письма. В этом случае все писавшие таким способом были «левшами». Возникновение направления письма слева - направо связано со сменой рук. То есть письмо стало производиться правой рукой и этот процесс во временном отношении непосредственно связан с формирования алфавита. Переход от слогового письма к алфавитному являлся революцией способа письма, при этом менялось направление письма и инструмент написания (в данном случае – руки). С точки зрения мозговой деятельности нервной системы произошло разделение рабочих функций в полушариях мозга. Левое полушарие приняло функции речи и логики, а правое полушарие «разгрузилось» и стало отвечать целиком за творческие процессы мозга. Подобные системы существуют в искусственном интеллекты и называются многопроцессорными или кластерными системами. Перераспределение функций обоих полушарий мозга обеспечило наиболее производительную деятельность мозговую деятельность, уменьшило затраты энергии для поддержания мозга в работоспособном состоянии. При этом стали возникать новые нейронные связи как в левом полушарии, так и между обоими полушариями мозга. Это и явилось так называемым увеличением массы мозга, которое до сих пор не могут объяснить ученые. Произошел постепенный переход от подвида древнего человека до современного человека. На рис. 4 показано распределение функций мозга по полушариям.
Рис. 4
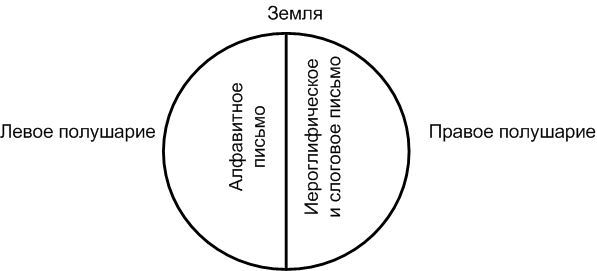
Леворукие писцы – это не только признак архаического письма, но и признак одаренности, поскольку правое полушарие мозга отвечает за творческие процессы, не поддающиеся пока научному анализу. Не исключено, что в сказе о «Левше» искусность ремесленника-кузнеца непосредственно связана с именем «Левша». Народное выражение «ум за разум зашел», вероятно, тоже связано с полушариями мозга человека. Потеря речи, координации движений опорно-двигательного аппарата человека является, как правило, нарушением функций левого полушария мозга. Ум – это функция левого полушария, разум – функция правого полушария. Потеря ума или сумасшествие означает метафору перехода (или потери) ума в область подсознания, т. е. «ум за разум зашел». В медицине это называется паралич мозга, в народе в этом случае говорят «хватил удар». Иероглифическое и клинописное письмо тоже, по всей видимости, связаны с правым полушарием мозга, несмотря на то, что производились как левой так и правой рукой писца, поскольку эти типы письма образные. Создание и чтение идеограмм требует образного мышления. Иероглифическое письмо сохранилось по настоящее время в письменных языках юго-восточной Азии, например, китайский, японский, корейские языки и др. В этом смысле интересно сравнить распространение языков на карте мира с полушариями головного мозга человека, где в левом полушарии мозга преобладают функции алфавитного письма и речи, а в правом – функции иероглифического и слогового письма и речи. На мировой карте распространения языков мы наблюдаем тождественное распределение письменных языков по полушариям земного шара (в сравнении с полушариями мозга), если мысленно соединить материки в праматерик Пангею и разделить надвое карту мира от полюса к полюсу через Персидский залив. В левом полушарии карты преобладают алфавитные языки, а в правом – иероглифические (ностратический алтайский язык и его производные, китайский язык, ностратический дравидийский язык). На рис. 5 показано условное распределение письменных языков на карте Земли, если провести вертикальную ось между полюсами.
Рис. 5
Феномен В. Мельникова до сих пор не могут научно обосновать, поэтому обращаются почти к мистическим гипотезам об открытии канала связи мозга В. Мельнокова с информационным полем мирового разума, существующего в биосфере Земли или космосе. Так утверждает учёный Виталий Фокин. На самом деле, всё гораздо проще. При поражении левого полушария у В. Мельникова сработал механизм перенесения языковых функции левого полушария мозга на правый, где как, было выше отмечено существует информация о первородном языке в виде таблицы первофонем. Первофонемы – это корни праязыка. При чтении текста или приёме речи на иностранном языке у Мельникова информация поступает сразу в правое полушарие мозга, минуя левое и обрабатывается в таблице первофонем, при этом включается виртуальная связь с таблицами хранения префиксов, суффиксов и окончаний опознанного языка. Например немецкое слово áuskundschaften – выведывать, разведывать (нем.) разбивается на aus-kund-schaft-en и преобразуется в iz-konc-shag-a-ti – из/от конца шагати/двигати (слав.). Выделяются корни kon – «конец» и shag – «шаг». Вероятно, способность читать иноязычные тексты проявилась не сразу, а по мере накопления информации в таблицах префиксов. Обучению языкам, так или иначе происходило при чтении текстов практически, незаметно для самого В. Мельникова, поэтому и кажется, что феномен заговорил сразу на разных языках. Особенность этого феномена в том, что он был русскоязычным. В истории отмечено ещё два полиглота, знающих около сотни языков. Это хранитель рукописей Ватикана. Вроде бы итальянец, но следует заметить, что в библиотеке Ватикана наверняка хранятся секретные рукописи на вульгарной латыни и этот язык архивариус мог знать ! Латынь была создана на основе вульгарной латыни, следовательно, вульгарная латынь или праславянский язык могла быть практически родным языком хранителя. Что такое родной язык ? Это когда говорящий на нём также и думает на этом языке. Вот почему иностранцам так тяжело даётся русский язык. Мышление на русском отличается от других языков. В чем это отличие ?
Ключевое слово да-нет
В русском языке есть слово при произнесении которого у иностранца производится помутнение в мозгу. Это слово существует только в русском языке и состоит из двух наречий, которые произносятся одновременно – да-нет. Может быть, слово да-нет дает ключ к пониманию развития мышления у ребенка. Слово да-нет – по-русски означает «ни то, ни се», может быть «да», а может быть и «нет», скорее всего «нет», но можно при желании и «да». То есть это слово дает возможность задающему вопрос как бы изменить ситуацию, если внести дополнительные условия. Слово да-нет – элемент эвристического мышления. С точки зрения информатики – это не жесткая логика или булева алгебра, а нелинейная логика которая срабатывает при нестандартных условиях. Это электронная ячейка, которая имеет неравновесное состояние. На стадии формирования речи, ребенок часто путает слово «на» со словом «дай». Это является этапом развития интеллекта. Не зря слова «на» и «нет», «да» и «дай» имеют почти одинаковое звучание. Слово «на» является антитезой слова «нет», а слово « да» является антитезой слова «дай». Чаще всего «да» и «на» выражает согласие и передачу предмета, а «нет» и «дай» - отрицание и захват предмета, хотя относятся к разным фонетическим группам. Эта казалось бы, смысловая путаница слов является ценнейшим инструментом для формирования логического мышления у ребенка. На мой взгляд, группа слов «да», «нет», «да-нет» в человеческой речи составляют элементы эвристического мышления, аналогичные искусственному интеллекту. Это тот самый механизм развития речи, который включается в мозгу у ребенка, когда он начинает различать предметы и произносить слоги «ба-ба», «ма-ма», да-да», «не-не», «дай-дай», «на-на». Слова «да», «нет», «на», «дай» по сути дела тоже слоги. Развитие речи и человеческого мышления возможно только в семье или за отсутствием семьи в человеческом окружении, общине. Именно это объясняет эффект детей-маугли, воспитанных в животной среде. Эти дети как бы приобретают или программируются на мышление животного и таким образом лишаются механизма речи и человеческого мышления.
Менталитет
Сейчас стало модно говорить о менталитете (характере) нации, который определяет особенности, наклонности, образ мышления, взаимоотношений в обществе определенной сообщности людей, проживающих на определенной территории. Менталитет неразрывно связан с языком, который формирует основные свойства поведения человека, наряду с воспитанием, наследственностью, влиянию звезд (астрология). Русскоязычная нация отличается от носителей другого языка высокой способностью к логическому мышлению и творческим функциям, благодаря особых речевых конструкций русского языка, о которых я упоминал ранее (функция «да-нет»). Логическое мышление позволяет выживать в чрезвычайно трудных условиях. Известна поговорка «Там, где русский выживает, немцу – смерть». Дуальность русского словотворчества хорошо известна про древнерусскому произведению «Слова о полку Игореве». В русском языке есть поразительные словные инверсные конструкции, которых нет ни в каком другом языке. В таблице 2 представлены слова-антонимы русского языка, полученные в результате инверсного чтения основного слова и простейших редукций. Таблица 2
Жесткая конструкция синтаксиса индоевропейских языков, построенная на латыни определяет характер человека строго дисциплинированного, целеустремленного, к таким нациям, например, относятся немцы, англичане. В тоже время свободная конструкция синтаксиса русского языка накладывает отпечаток на русскоязычного человека, который неустойчив в поведении, подчас безалаберен, в то же время свободный русский язык дает импульсы к творчеству и изобретательности. Появление феномена В. Мельникова не говорит о том, что всем русским необходимо бить головы, чтобы стать полиглотами, НО можно, путём постепенного практического освоения методики поиска корней добиться хотя бы приблизительных и вполне приемлемых результатов В. Мельникова и вам откроются удивительные тайны многих языков. Сначала, пользуясь вспомогательными словарями вы научитесь угадывать в незнакомом слове родной корень, затем, уже самостоятельно, работая с незнакомым текстом вы постепенно начнёте понимать значение иностранных слов. И, поверьте мне, вы испытаете огромное творческое удовлетворение. Вы убедитесь в том, что слова внешне совершенно различные могут иметь на самом деле много общего и это общее имеет славянские корни ! Вы откроете для себя новый мир, это будет увлекательным приключением в мире слов для человека любого возраста, от школьника до почтенного пенсионера.
Фонетика
В разделе «Фонетика» вместо традиционной оглассовки звуков букв я представлю метод поиска славянских корней в иностранных словах. Поскольку этот метод является главным в понимании происхождении новых слов в языках. Предлагаемая в современных учебниках иностранных языков транскрипция звуков и описание их артикуляции всё равно не дает никакого положительного результата. Например, для произношения в английском языке буквосочетания «TH» требуется, как пишут, просунуть кончик языка между зубами и выдохнуть. В итоге, на практике, у одних учащихся получается звук похожий на русское «Д», у других – на русское «З». Научиться говорить без акцента можно только, находясь в природной среде изучаемого языка, то есть среди англичан, в данном примере. Слово в языке состоит из слогов, кирпичиков, фонем из которых складывается слово. Первоначально слово у первобытного человека возникло из звуков, подражающих природным звукам животных и птиц.
Таблица 3 звуков человеческой речи, подражающих природе
Таблица 3
Из природных звуков складывалась человеческая речь в виде повторяющихся слогов. Во многих современных языках аборигенов, например, полинезийском языке, сохранилась слоговая, повторяющаяся форма слова. И даже в современные язык, например, в иврите : «gal-gal» - колесо/kol-kol – колесо-колесо (праслав.)(ред. k/g). На основе праязыка сформировался ностратический язык, который включает шесть самостоятельных групп языков : - алтайская; - уральская; - дравидийская; - индоевропейская; - картвельская; - семито-хамитская. Славянская подгруппа языков входит в состав индоевропейской группы. Анализ сравнительного словаря В.М. Иллича-Свитыча [7] показал, что славянкая группа языков присутствует практически во всех известных группах ностратического языка. Это означает ведущую роль праславянского языка в формировании ностратического языка.
Предыстория вопроса
Предлагаемый метод определения в индоевропейских письменных языках славянских слов, основан на законе братьев Гримм (первое германское передвижение согласных) и методике А. Н. Драгункина [2], В. Н. Тимофеева. Закон братьев Гримм: «Первое германское передвижение согласных (также — первый сдвиг согласных, закон Гримма, в англоязычных источниках также закон Раска-Гримма) — фонетико-морфологический процесс в развитии германских языков, заключавшийся в изменении индоевропейских смычковых согласных смычных согласных. Впервые описан Расмусом Раском, однако полностью сформулирован и исследован Якобом Гриммом, чье имя в конечном итоге и получил. С точностью известно лишь, что первое передвижение согласных происходило в общегерманскую эпоху, и потому жестко и обязательно представлено во всех германских языках, живых и мертвых. Потому справедливо утверждение — если в индоевропейском языке обнаружено в полной мере наличие перехода по закону Гримма — язык необходимо принадлежит к германской группе. Закон Гримма вне германских языков В течение двадцатого века появились и стали настойчиво накапливаться факты, что передвижения согласных, частично, а возможно, полностью, повторяющие закон Гримма происходили и происходят в негерманских и даже неиндоевропейских языках. Так БСЭ ссылается на чадские языки, где — по-видимому, под субстратным влиянием зафиксирован сдвиг согласных. При исследовании хеттского языка на подобное же явление обратил внимание Бедржих Грозный. Существуют следы перехода глухих смычных в спирант в древнеяпонском языке. В литературе проскальзывают намеки, что, возможно, это связано с языковой типологией или некими ассимилятивными процессами. Так, А. А. Леонтьев при описании языка бурушаски обратил внимание, что оглушение звонких происходит несколько неожиданно в интервокальной позиции. Единого решения проблемы не на данный момент наука не имеет.» [6]. Удивительно, но в круг исследования передвижения согласных филологов и лингвистов никак не попадают славянские языки, которые в Европе по сути дела являются подавляющими как по количеству, так и по числу говорящих на этих языках !!! Второй вопрос, а если в славянском языке существует редукция согласных, то он автоматически принадлежит к германской группе языков ? ! Автор данной работы провел ряд исследований по происхождению слов английского, французского, латинского, греческого, этрусского и других языков. Результаты исследования легли в основу этимологических словарей иностранных слов, разработанных оригинальным методом поиска славянских корневых слов в иностранных словах.
Метод восстановления праславянских корней в индоевропейских языках
Метод состоит из следующих положений: 1. Использовать редукцию согласных r/l, l/r, p/b, b/p, d/t, t/d, f/v, v/f, s/t, t/s, g/h, k/h. 2. Использовать замену букв: f на d, w > g, w > m, l > j, p > b, y > v, v/j, m > n, k > x, b > k, b > m, d > cl, возникшую в результате cходности начертания букв. 3. Использовать инверсию слова, которая возникла из-за смены направления письма. 4. Учитывать слова-основы такие как dis/sid (инверсия) – зад (слав.), con – конец (слав.), применяемые как приставки для формирования слов английского языка. 5. Учитывать, что иностранные слова во многом имеют происхождение от латыни или точнее народной латыни, которая основана на базе славянских языков. 6. Учитывать то, что одно иностранное слово может состоять из 1, 2 и более славянских слов.
Многозначность иностранных слов
В языках германской и романской группы существует хорошо известная многозначность слов. Проще говоря, одно слово может иметь множество смысловых значений при переводе на русский язык. Например, английское слово cap имеет следующие значения, указанные в таблице 4 (второй слева столбец):
Таблица 4
Общий смысл этих слов в общем понятен и состоит в описании головного убора различными терминами и действия с этим головным убором. В конкретном переводе слова cap возникают проблемы точного подбора слов (подбор по смыслу) текста и месте слова cap в предложении (существительное, глагол). Отчего возникла эта проблема ? И неужели у русских слов, переведенных с английского слова cap существует единственный исторический корень cap ? Конечно нет. Дело в том, что на раннем этапе формирования слова cap в английском письме это слово имело разные фонетические оттенки, заимствованные от различных славянских слов (см. столбец 3 -5, таблица 1). Кроме того, разночтение получается из традиционной редукции согласных, перестановки, пропуск букв и самое главное из-за замены сходных в написании букв латинского алфавита. Многозначность английских слов, вероятно, возникла на этапе формирования английского письма, и главное, на этапе формирования строчных букв. Английское письмо возникло на основе древнерусского письма, которое писалось на латинице, и более того, писалось справа налево, как этрусское и венетское письмо. Отсюда и возникновение в английском языке множества инверсий славянских слов.
Редукция согласных
В письменных языках германской и романской группы существует традиционная редукция согласных, основанная на законе братьев Гримм. К традиционной редукции согласных относятся следующие пары букв: r/l, l/r, p/b, b/p, d/t, t/d, f/v, v/f, s/t, t/s, g/h, h/g, k/h, h/k. В табл. 5 даны примеры редукции гласных.
Таблица 5
Сходство букв при написании
В латинском алфавите существуют сходные в написании буквы, которые при формировании слов германской и романской группы могли переходить одна в другую. Латинские строчные буквы, если внимательно присмотреться, состоят из легко различимых начертательных элементов типа: вертикальная палочка, кружок, черта, крючок. Например, строчная буква d состоит из кружка слева и палочки справа – o, I; буква j - из крючка с загибом влево, буква l - из крючка с загибом вправо и т. д. Таким образом, при переписке текстов древнеславянского языка возможен умышленный или неумышленный переход одной сходной строчной буквы в другую в результате смещения палочек, кружков, черточек по линии письма. Это можно назвать косвенной редукцией согласных, то есть это является не фонетической (звуковой) редукцией согласных, а начертательной редукцией согласных ! Это и является основной причиной многозначности иностранных слов. Формирование косвенной редукции гласных, по мнению авторов, связано с возникновением в 8 веке скорописных и курсивных почерков на основе строчных букв (минускул) в противоположность прописных букв латинского алфавита. Понятно, что скоропись требует и упрощенного начертания букв (см. таблица 3). Упрощенность написания строчных букв привела и к ложной трактовке древнеславянских источников письма (полностью утерянных в средние века), с которых практически формировались современные иностранные языки.
Таблица 6
Продолжение Таблицы 6
В таблица 7 представлено сравнение букв латинского, этрусского, венетского алфавитов, сходных в написании.
Таблица 7
В таблице 8 представлено сравнение строчных букв латинского и древнеславянского алфавитов.
Таблица 8
Латинские буквы m/n, l/j, k/х, b/p/d/q/c в написании трудно различить. Буква w (ω) состоит из двух кружков, которые могли трактоваться переписчиками как буква p, g или обеими буквами. Смещение вертикальной черты в латинских буквах р и b приводит к редукции р/b и наоборот. Написание латинской буквы v могла трактоваться переписчиками как буква y.
Инверсия слова
В письменных языках германской и романской группы существуют слова, которые имеют инверсное написание, т. е. эти слова имеют перевод на русский язык в инверсном чтении. В таблице 9 приведены примеры инверсий.
Таблица 9
Инверсия английских слов возникла в результате остаточной инверсии от древнеславянского письма, которое писалось справа налево, в отличии от современного традиционного письма слева направо. Остаточная инверсия в английских словах существует и в виде приставок и окончаний, например, un (англ.) – ni – не – (русск.); ing (англ.) – nai – най, ние – (русск.)
Слова-приставки
В письменных языках германской и романской группы существуют слова-приставки типа dis/sid (инверсия) (англ., фр.)– зад (слав.), con (англ., фр.) – конец (слав.), contre (англ., фр., лат.) – con-obr- конец обратный (слав.)/protivnij – противный (слав.); durch (нем.) – дырка (слав.). Исторически слова-основы восходят к латинскому языку, в котором имеют те же значения. Примеры применения слов-приставок в английском, немецком, французском и латинском языках даны в таблице 10 - 13.
Таблица 10
Таблица 11
Таблица 12
Таблица 13
Активное применение слов-приставок (по происхождению относятся к вульгарной латыни – древнеславянский язык) в германской и романской группе языков говорит о том, что первоначально эти приставки имели самостоятельные функции (что очень хорошо видно в славянских языках), которые определяли основные части человеческого и животного тела, как совершенно справедливо отмечал А.Н. Драгункин [2].
Латинские слова
Как известно в русском языке имеется множество иностранных слов латинского происхождения. Не лишены этого и языки германской и романской группы. К сожалению, снова приходиться констатировать, что русскоязычное население России адаптировало латинские слова, которые исторически принадлежат славянским языкам. Например, слово адепт, производное – адаптировать вроде бы пришло к нам из латинского языка (adeptus, буквально – достигший, посвященный в тайны какого-либо учения - БСЭ). Но, что значит слово адаптировать в русском языке ? Адаптировать – «принять как есть, приспособить для удобства». Если перевести adeptus на древнеславянский, то получаем слово udobnij – удобный (слав.). Это ли не есть истинное значение слова ?! Иногда просто диву даешься, читая в БСЭ происхождения иностранных слов. Авторы не призывают все переиначить. Но, знать историю, истинное происхождение иностранных, да и славянских слов жизненно необходимо для правильного понимания природы, мира и места человека в этом мире.
Сложносоставные слова
В славянских языках присутствуют сложносоставные слова (например, природоведение – природой - ведать), но не в таком количестве как в иностранных словах, которые буквально насыщены подобной структурой слова. И это вполне понятно, если учесть, что иностранные слова постороены на составных славянских корнях. В английском языке существуют целые слова-фразы в переводе через древнеславянский язык. Примеры сложносоставных слов в английском языке приведены в таблице 14.
Таблица 14
Пропуск и подстановка букв
При преобразовании английских слов в древнерусский эквивалент наблюдаются довольно частые пропуски и подстановки букв, которые еще предположил А. Н. Драгункин в своей книге [2], например, пропуск и подстановка буквы s. Характерные образцы пропусков и подстановок букв в английских словах даны в таблице 15. Пропуски букв выделены курсивом, а подстановки выделены в квадратные скобки.
Таблица 15
Перестановка букв
При поиске славянских корней в иностранных словах необходимо учитывать возможную перестановку букв. При этом следует пронимать, что перестановка букв нежелательная операция, поскольку может привести к искажению смысла слова. Поэтому перестановка требуется только при убедительном доказательстве данной операции. Примеры перестановок в английском языке приведены в таблице 16.
Таблица 16
Морфология
Приставки (префиксы) существительных и глаголов
Слово в языке состоит из корня слова, приставки, окончания и суффикса. Основной частью слова является корень (основа), который как-бы обрастает мясом дополнительных приставок. Среди приставки слова следует различать простую приставку и приставку-слово, формирующую составное слово. Простые приставки : a-, ab, ad-, an-, de-, di-, e-,ex-, in-. Сложные приставки : com- конец, con- конец, contr-против, dis-задний, hex- шесть, bios- жить и др.. Перечень приставок сведен в таблицу 17.
Таблица 17
Примечание : 1. Греческие слова даны в латинской транскрипции. 2. Жирным шрифтом выделены слова-основы.
продолжение табл. 17
Метод поиска корня:
145 составных слов, котрые потрясут основы научного мира. Знание значений этих слов позволят вам свободно читать научные тексты, не обращаясь к словарю иностранных слов, кроме того, эти слова входят во все западноевропейские языки. Таким образом, без специального изучения языков вы будете иметь основательный словарный запас.
1. авиа…avia- – птица (лат.)/penij – пение (праслав.)(пропуск p, замена n/v). 2. авто, ауто… autos- – сам (греч.)/samij – самый (праслав.)(пропуск s, замена m/n-u, j/t). 3. агро… agro - – поле (греч.)/pagit – пажить (праслав.)( пропуск p, замена t/r)/ paxotnij – пахотный (праслав.)( пропуск p, редукция x/g). 4. аква…akua- – вода (лат.)/ква-ква (праслав.) ква - кваканье лягушки/vodnaj – водный ((праслав.)(пропуск v, замена d/q). 5. акус… akustikos - – слуховой, слушающий (греч.)/uxij – ухий (праслав.)( редукция x/k). 6. амфи… amphi - – с обеих сторон (греч.)/obboj –обе (стороны) (праслав.)( редукция b/m, b/ph). 7. анемо… anemos- - ветер (греч.)/vejanij – веяный (праслав.)( замена v/n, jn/m). 8. анти…anti - – против (греч.)/protiv –против (праслав.)( пропуск p, замена r/n). 9. антропо.. anthropos -– человек (греч.)/poludna – полюдий/людина (праслав.)(инв. слова anthrop, редукция l/r, d/th). 10. архео… archaios- – древний (греч.)/starikan – старикан (праслав.)( пропуск st, редукция k/ch). 11. архи… archi- - старший, главный (греч.)/ starshij – старший (праслав.)(пропуск st, редукция sh/ch, замена j/i). 12. астро… astron- - звезда (греч.)/le[s]tnaj – лётная (пропуск l). 13. аэро…aer- - воздух (греч.)/jarij - ярый (праслав.)( пропуск j). 14. бактерио… bakterion - - палочка (греч.)/palkij – палка (праслав.)(перест. k/t, замена l/t). 15. бальнео…balneum - - баня, купание (лат.)/banja – баня (праслав.)(перест. l/n, замена j/l). 16. баро… baros- - тяжесть, вес (греч.)/tjag – тяж (праслав.)(инв. слова baros, пропуск t, замена j/r, g/b). 17. бати…bathis- - глубокий (греч.)/glubinj – глубинный (праслав.)( замена g/b, b/t, n/h, пропуск l)/donij – донный (праслав.)( замена d/b, n/h). 18. би…bis- - дважды (лат.)/dvoj – двой/два (праслав.)( замена d/b, v/I, j/s). 19. ...био - bios – жизнь (греч.)/ biti -быти (праслав.). 20. вибро…vibro - - колеблю(сь) (лат.)/colebanj –колебание (праслав.)( инверсия слова vibro, пропуск с, редукция l/r, замена n/v). 21. видео…video - - смотрю, вижу (лат.)/ videti – видети (праслав.). 22. вице… vice - - вместо, взамен (лат.)/vmesto – вместо (праслав.)( пропуск m, замена st/c). 23. гастро… gaster- - желудок, чрево (греч.)/geludoc – желудок (праслав.)( пропуск l, замена d/st, c/r). 24. гелио…helios- - солнце (греч.)/luch – луч (праслав.)( инверсия слова heli, редукция ch/h). 25. гемато, гемо… haimatos - - кровь (греч.)/krovnaj – кровный/кровь (праслав.)( пропуск r, замена v/i,n/m). 26. гетеро… heteros- - иной, другой (греч.)/inojij – иной (праслав.)( пропуск i, замена n/h, j/t, j/r). 27. гига… gigas – гигантский (греч.)/velikaj – великий (замена v/g, l/i, редукция k/g). 28. гигро… hidros- - влажный (греч.)/vlagnij – влажный (праслав.)( замена v/h, l/i, g/d, n/r)/vodnij – водный (праслав.)( замена v/h,n/r)/gidkij – жидкий (праслав.)( редукция g/h, замена c/r). 29. гидро…hydos- - вода (греч.)/vodnij /gidkij – водный/вода/жидкий (праслав.)( замена v/h, пропуск n). 30. гипер… hiper- - над, верх (греч.)/ verxij – верхий/верх (праслав.)( замена v/h, x/p, j/r, пропуск r). 31. гипо… hypo- - под, внизу (греч.)/nige – ниже/низ (праслав.)(замена n/h, i/y, g/p). 32. гиро… giros - - круг (греч.)/crug – круг (праслав.)(инв. слова gir, пропуск c, замена u/i). 33. глотто… glotta – язык (греч.)/glotati/glotka/glаs – глотати/глотка/глас (праслав.)( редукция s/t). 34. гомео… homoios- - подобный, одинаковый (греч.)/shodnij – сходный (праслав.)( пропуск s, замена d/o, n/m). 35. гомо… homos- - равный, одинаковый (греч.)/ shodnij – сходный (праслав.)( пропуск s, замена d/o, n/m). 36. ...ген – gen - рождающий (греч.)/gen – жена, женити/род (праслав.)(инв. gen). 37. …генез – genesis – происхождение, возникновение (греч.)/ geniti – женити (праслав.)( редукция t/s). 38. гео… ge- - земля (греч.)/zem – земля (праслав.)( редукция z/g, пропуск m). 39. ...гнозия - gnosis – познание, наука (греч.)/-znat – знати (праслав.)(редукция g/z, s/t). 40. ...гония – gone, goneia – рождение, потомство (греч.)/ gen/kolenij – жена, женити/колено (праслав.)(редукция k/g, пропуск l). 41. ...грамма - gramma – черта, буква, написание (греч.)/ skrabnj – скрябание/скрипение (прасл.)(пропуск s, редукция k/g, b/m, замена n/m). 42. ...граф – grapho- пишу (греч.)/scrabati- скрябати/писати (стилом) (праслав.)/по камню (первый предмет для письма) скребли, а не писали (редукция sc/g). 43. ...графия – grapho - пишу, черчу, рисую(греч.)/scrabo- скрябати/писати (праслав.). 44. дека… deka- - десять (греч.)/desjat – десять (праслав.)( редукция sj/c-k, пропуск t). 45. дендро… dendron - - дерево (греч.)/drevij – древий/древо (праслав.)( замена r/n, v/d, j/r). 46. демо…demos- - народ (греч.)/dim/dom – дым/дом (праслав.). 47. дермато… dermatos- - кожа (греч.)/cojnaj – кожный (праслав.)( замена c/d, j/r, n/m, j/t)/scornij – скорный (.праслав.)(пропуск s, замена c/d, j/r, n/m, j/t)/dranаj – драный (праслав.)( замена n/m). 48. деци… decern- - десять (лат.)/desjat – десять (праслав.)( редукция s/c, замена j/r). 49. дина…, динамо… dynamis- - сила (греч.)/dvigаnij – двигание (праслав.)( замена v/y, g/n, ni/m). 50. зоо… - zoon- – животное, животное существо (греч.)/zver – зверь (праслав.)(замена oo/w-v, r/n). 51. идео… idea- идея, образ, понятие (греч.)/dejanij – деяние (праслав.)(перест. d/i, замена j/i, пропуск n). 52. идио… idios- - свой, своеобразный, особый (греч.)/svoj – свой (праслав.)( перест. i/d, замена s/d, v/i, j/i). 53. изо… isos- - равный, одинаковый, подобный (геч.)/svoj – свой (праслав.)( перест. i/s, замена v/i). 54. иммуно… immunitas- - освобождение, избавление (лат.)/iz-bavlenij – избавление (праслав.)( замена z/m, v/u, редукция b/m, пропуск l). 55. ихтио… ichthys- - рыба и фауна (греч.)/piskarij – пескарий/пескарь (праслав.)( пропуск p, редукция sk/sh, замена r/th). 56. карбо…, карбон… carbonis – уголь (лат.)/ ca[r]menij – каменный (праслав.)( редукция m/b). 57. квази… quasi- - нечто вроде, как-будто, как бы (лат.)/kazanij – казанный (праслав.)( редукция k/qu, z/s, пропуск n). 58. кине…, кино… kinema- - движение (греч.)/gonimij/dvigimij/konnij – гонимый/движимый/конный (праслав.)( редукция g/k, замена d/k, v/i, g/n). 59. кино… kynos- - собака (греч.)/gavkati – гав-гав/гавкати (праслав.)( редукция g/k, замена v/y, k/n). 60. код… codex – собрание законов (лат.)/svod – свод (праслав.)( редукция s/c, пропуск v). 61. комм… communis- - общий (лат.)/soobbchij – сообщий (праслав.)(редукция s/c, b/m, замена ch/n). 62. космо… kosmos- - мир, Вселенная (греч.)/ coobchij – сообщий (праслав.)(редукция s/k-c, b/m, ch/s, перест. s/m). 63. крио…krios- - холод, мороз, лёд (греч.)/xlad – хлад (праслав.)(редукция x/k, l/r, пропуск d). 64. крипто…kryptos- - тайный, скрытый (греч.)/skri[p]tij – скрытый (праслав.)( пропуск s)/skrjabij – скрябанный ((праслав.)( пропуск s, редукция b/p). 65. ксило… xylon- - срубленное дерево (греч.)/xvoja – хвоя (ель, сосна) (праслав.)( замена v/y, j/i). 66. ...логия – logos – слово, учение (греч.)/slovo/slog/gol – слово/cлог/голос (праслав.)(пропуск s; инверсия слова). 67. лексико... lexikos- – относящийся к слову (греч.) /rechenij – реченый (праслав.)(редукция r/l, ch/x,замена n/k). 68. ...ман – mania – безумие, восторженность, страсть (греч.)/maniti – манити (праслав.) 69. ...метр – metron – мера (греч.)/mert – меряти (праслав.)(перестановка t/r !!!). 70. лакто… lactus - - молоко (лат.)/lacati/mleco – лакати/млеко (праслав.)( пропуск m). 71. ларинго… laryngos- - гортань (греч.)/gorlo – горло (праслав.)(инв. laryg). 72. лейко… leukos- - белый (греч.)/belenkij – беленький (праслав.)( пропуск b, замена n/u). 73. лиз…, …лиз..lysis- - разложение, растворение, распад (греч.)/razlogj – разложение (праслав.)( редукция r/l, z/s 74. лимфа…lympha- - чистая вода, влага (лат.)/vlagnij – влажный (праслав.)(инв. слова lymph, редукция v/f-ph, пропуск l, замена g/m, j/l). 75. линго…lingua- - язык (лат.)/jazik – язык (праслав.)( замена j/l, z/n, редукция k/g). 76. лито…lithos- - камень (греч.)/plita – плита (праслав.)(пропуск p). 77. макро…macros- - большой (греч.)/moguchij – могучий (праслав.)( замена g/c, пропуск ch). 78. мега… megas- – большой (греч.)/moguchij – могучий (праслав.). 79. медиа… mediantus – находящийся посредине (лат.)/megdu – между (праслав.)( пропуск g). 80. мезо…mesos- - средний, промежуточный (греч.)/megij – межa (праслав.)( редукция g/s). 81. мело…melos- - песнь, мелодия (греч.)/melodij – мелодия (праслав.)(пропуск d). 82. мета…meta- - между, после, через (греч.)/mega- межа (праслав.)( редукция g/t). 83. микро… micros- – малый, маленький (греч.)/malij – малый (праслав.)( редукция l/r). 84. мио…mys- - мышца (греч.)/mishc – мышца (праслав.)( редукция sh/s, пропуск c). 85. моно…monos- - один, единый, единственный (греч.)/edinij – единый (праслав.)( пропуск e, замена d/m). 86. морфо…morphe- - вид, форма (греч.)/forma – форма (праслав.)(инв. слова morph, редукция f/ph, перест. o/r). 87. мото…motor- - приводящий в движение (лат.)/motanij – мотание (праслав.)(замена n/r). 88. мульти…multum- - много (лат.)/mnojij – множий/многий (праслав.)( замена n/u, j/l, j/t). 89. нано… nanos- – карлик (греч.)/malij – малый (праслав.)( замена m/n, l/n)/korotij – короткий (праслав.)( замена k/n, r/n). 90. невр…, невро, нейро…neuron- - жила, нерв (лат.)/nerv- нерв (праслав.)(перест. u/r)/jilnij – жильный (праслав.)(инв. слова neur, замена j/r, l/e). 91. некро…nekros – мёртвый (греч.) ne-krov – нет-крови (праслав.)( пропуск v). 92. нео…neos- - новый (греч.)/novj – новый (праслав.)( пропуск v). 93. ...ома – оma – опухоль (греч.)/kom –ком (праслав.)( пропуск k !!!). 94. окси…, окс… - oxys - - кислый (греч.)/kuslj – кислый (праслав.)( редукция k/x, пропуск l). 95. орто…orthos - - прямой, правильный (греч.)/prjamoj – прямой (праслав.)( замена p/o, j/t, m/h). 96. ото…otos- - ухо (греч.)/uxo – ухо (праслав.)(замена x/t). 97. палео…Palaios - - древний (греч.)/proshlij – прошлый (праслав.)( редукция r/l, пропуск sh, замена l/i). 98. пара…para- - возле, мимо, вне (греч.)/para – пара/парный (по ту сторону) (праслав.). 99. пато…pathos- - страдание, болезнь (греч.)/bolnoj/padij – больной/падший (праслав.)( редукция b/p, d/th, замена l/t, n/h). 100. пери…peri- - вокруг, около, возле (греч.)/ocolij – околий/около (праслав.)( пропуск o, замена c/p, редукция l/r). 101. пико…pico - - малая величина (исп.)/melcij – мелкий (праслав.)( редукция m/p, пропуск l). 102. пиро…pyr - - огонь (греч.)/pilati – пылати (праслав.)( редукция l/r). 103. плазма…plasma- - вылепленный, оформленный (греч.)/plastanij – пластанный/пластелин (праслав.)( пропуск t, замена ni/m). 104. поли…polys- - многий, многочисленный, обширный (греч.)/mnojij – множий/многий (праслав.)( редукция m/p, j/s, пропуск n, замена j/l). 105. прото…protos- - первый (греч.)/pervij – первый (праслав.)(перест. o/r, замена v/t). 106. псевдо…pseudos- - ложь (греч)/vimishlenil – вымышленный (праслав.)( пропуск v, редукция m/p, sh/s, замена l/e, n/u, j/d). 107. психо…psyche- - душа (греч.)/dushevnij – душевный (праслав.)( замена d/p, n/h, v/u, редукция sh/s). 108. радио…radio > luchevoj – лучевой (праслав.)( редукция r/l, замена ch/d, v/i). 109. санти…sentum- - сто (лат.)/sotnja – сотня (праслав.)(перест. n/t). 110. склеро…skleros- - твёрдый (греч.)/stekljanij – скляный/стеклянный (праслав.)( пропуск t, редукция l/r, замена n/r). 111. ...скоп – skopeo – смотрю (греч.)/poisk –поиск (праслав.)(инверсия слова, пропуск i). 112. сейсмо… seismos – колебание, землетрясение (греч.)/smechati – смещати (праслав.)(перест. s/m, замена ch/s). 113. социо…socialis- - общественный (лат.)/sosednij – соседний (праслав.)( редукция s/c, пропуск d, замена n/l). 114. суб…sub- - под, около (лат.)/pod- под (праслав.)(инв. слова sub, редукция p/b, замена d/s). 115. супер…super- - сверху, над (лат.)/sverx- сверх (праслав.)(перест. p/r, замена x/p). 116. сфера…sphaira- - шар (греч.)/s[p]har – шар (праслав.). 117. теле…tele - - вдаль, далеко (греч./dale – далее (праслав.)( редукция d/t). 118. тера…teras- - чудовище (греч.)/ujas – ужас (праслав.)(инв. слова tera, замена j/r, редукция j/t). 119. термо…therme- - тепло (греч.)/teplo- тепло (праслав.)(перест. r/m, редукция p/m, l/r). 120. техно…techne - - искусство, мастерство, умение (греч.)/tochnij – точный (праслав.). 121. ...типия –typos – отпечаток (греч.)/pjata – пята (праслав.) 122. ...трон –сокращение слова «электрон» - греч. слова нет !!!/nutro – нутро (праслав.)( инверсия слова, перестановка t/r). 123. ...тропия – tropos – поворот, направление (греч.) / trop - тропа (петлять !!!) (праслав.)/soport – супороть-напупороть !!! (стоять напротив друг друга)( инверсия слова). 124. ...тика – tika (греч.)/– tika/-kita – кита (строение, скит, Китай-город, Китеж) (праслав.)( инверсия слова)/strjka – стройка (прасл.)(пропуск s, r). 125. ультра…ultra- - сверх, за пределами, по ту сторону (лат.)/verxnj – верхний (праслав.)( замена v/u, x/t, n/r, редукция r/l). 126. уни…unis- - один (лат.)/odin- один (праслав.)( замена d/n). 127. уро…uron- - моча (греч.)/pur > moch – моча – (праслав.)(пропуск p, редукция m/p, замена ch/r). 128. ...фаг - phagos – пожиратель (греч.)/- pag- пожирати (праслав.)/hap – хапати (праслав.)( инверсия слова, редукция g/h). 129. фенто…femten- - пятнадцать (дат.)/pjat-na-desjat – пять-на десять (праслав.)( замена p/f, редукция d/t). 130. ферро..ferrum- железо (лат.)/geleznij – железный (праслав.)( редукция g/f, l/r, замена n/r, пропуск z). 131. ...фикация –facio – делаю (греч.)/vajti – ваяти (праслав.)(редукция v/f, замена t/c). 132. фил…, фило…phileo – люблю (греч)/lubij – любый (праслав.)(инв. слова, phil, редукция b/ph). 133. фото… photos- – свет (греч.)/foto- svet – свет (праслав.)(замена f/ph, редукция v/f, пропуск s). 134. фито… phiton- – растение (греч.)/vita-jiti – жити (праслав.)(замена f/ph, редукция v/f). 135. фобия…phobos- - страх, боязнь (греч.)/bojazn – боязнь (праслав.)(инв. слова phob, замена j/f/ph). 136. фоно…phone- - звук (греч.)/zvon – звон (праслав.)(замена zv/ph). 137. …цитo – kytos- – вместилище, клетка (греч.)/klet – клеть (праслав.)( замена l/y). 138. хромо…chroma- - цвет, краска (греч.)krasnij – красный (праслав.)( редукция k/ch, пропуск s, замена ni/m). 139. хроно…chronos- - время (греч.)/vremja – время (праслав.)(замена v/ch, m/n). 140. эври…eurys- - широкий (греч.)/shirij – ширий/широкий (праслав.)( пропуск sh). 141. экзо…exo- - вне, снаружи (греч.)/vne- вне (праслав.)( замена v/x, пропуск n). 142. эко…oikos- - жилище, местопребывание (греч.)/kojka – койка (праслав.)( пропуск k, замена j/i). 143. эндо…endon- - внутри (греч.)/nutro – нутро (праслав.)( редукция t/d, пропуск r). 144. этимо... etymo- – истинное значение слова (греч.) /istina – истина (праслав.). 145. этно…ethnos- - племя (греч.)/edinij – единый (редукция d/th). Прочитали ? Теперь, у вас включился механизм ассоциативной памяти. Ассоциация – associater – ssoedinjati – соединятi (праслав.). Не тот, что дается в учебнике «langEasy» c механически запоминанием слов, связанных в цепочки образов. Теперь вы запомните незнакомые слова, образы букв которых вам знакому по родному языку. Например, геческое слово bio- состоит из букв b, i, o. А в ассоциативной таблице вашей памяти лежат русские буквы Б и И, что сливаются в слово БЫть (существовать). Вспомнив о редукции b/v, вы найдёте латинское слово vita, которое трансформируется, благодаря вашей таблице в слово jiti – ЖИть. Каждое иностранное слово у вас вызывает живой образ, связанный с русский словом, а не простой ассоциации слов bio- жить. Используя законы редукции и словообразования (из моего метода) вы в слове bio- нахотите славянский корень и корень латинского слова vita-. Разве это не удивительно ?
tvoroge Примеры применения сложных приставок:
- био-логия (жизнь-слово) – совокупность наук о живой природе - фаго-циты (жрать-клетка) – защитные клетки животных - генетика – (жена-строение) - наука о наследственности - антропогенез (человек-поколение) – наука о происхождении человека
Окончания глаголов
Трансформация окончания глаголов в инфинитиве из праславянского языка :
-ti > - ть – русский язык (основа + -ть) -ti > -ri > -ir, -er – латинский язык (основа + -er) -er > -er, -re, -ir – французский язык (основа + -er, -re, -ir) -er > -ar, -er, -ir – испанский язык (основа + -аr, -еr, -ir) -er > en – немецкий язык (основа + en) -ti > to служебное слово перед основой глагола английского языка (to + основа) -re > le-, li- - служебное слово перед основой глагола иврита (le- + основа) -ti > it > -itum – санскрит (основа + -itim) -ti > -to > -o – греческий язык (основа + -о). (Прим. греческий язык не имеет инфинитива)
В табл. 18 представлены окончания инфинитива глагола в иностранных языках
Таблица 18
продолжение табл. 18
Примеры: Корни глагола можно получить, отделяя приставку и окончание глагола от основы как показано в таб. 19.
Таблица 19
Примечание : 1. греческие глаголы даны в латинской транскрипции. 2. значения греческих глаголов exo- «иметь», eimai – «быть», на мой взгляд, переставлены местами в греческом языке, судя по корневой основе. Однако, если обратиться к исходному праязыку, то глаголы «быть» и «иметь» имели общее значение «есть, принимать пищу», «хавать», «амать», «ам-ам», от сюда и основы hav, am, es – есть, не в смысле существовать, а принимать пищу. Аз есмь – «я есть» или Аз е[c]м – «я ем». Потому что, пища дает человеку возможность жить, быть, существовать.
Местоимения
В иностранных языках различаются следующие категории местоимений: - личные; - возвратные; - притяжательные; - указательные; - определительные; - относительные; - вопросительные; - неопределённые; - отрицательные.
Личные местоимения
Личные местоимения склоняются по падежам. «Падежные окончания личных местоимений в индоевропейских языках совершенно различны и не воcходят к архетипам; общность есть только в основах» [5]. В таблице 20 представлены личные местоимения в именительном падеже для группы самых распространённых языков.
Таблица 20
Продолжение таблицы 20
Формирование корней личных местоимений в именительном падеже (номинативе): местоимения 1, 3 лица формируются от слова «яйцо» - jajk > Jk.
Реконструкция местоимения Я
Решение мы находим в древнеегипетском языке, где иероглиф «яйцо» имеет два значения: «яйцо» и «ум», «мудрый». Двумя же формами представляется местоимение 1-го лица: *eg’Ho(m) и *mV (!). Сюда же относится перевод древнеегипетского иероглифа «птенец»- я, мне, мой, она. рука-сова- сова-яйцо - amm - мозг (др.-егип.) > Rk/Drt+m+m+Jjk > kurinj jajk/mudrj lik/ delat umnj lik - куриный яйцо/мудрый лик/делать умный лик (слав.)( перест. r/k; перест. d/r, инв. drtm) > brain> mudr - мудрый (слав.) птенец - w - свойство, собственность (др.-егип.) > w > svj - свой (слав.)(пропуск s, замена v/w) птенец- 3 черты - они, им, их (др.-егип.) > w+tri >voji - свои (слав.)( замена v/w, пропуск s) > they, them, their (англ.) > svji - свои/jim - им/jih - их (слав.) птенец - муж - wi - я, мне, мой (др.-егип.) > mj (muj) - мой, моё, моя (муж) (слав.)(замена m/w) > I, me (англ.) > jg/mj - яйкий/мой (слав.) птенец - wi - я, мне, мой/как ! (др.-егип.) > w > moj/vaj - мой/вай ! (слав.)( замена m/w; v/w)
Реконструкция местоимений Он, Она
К сожалению, реконструкция и показатели местоимений третьего лица и, в, частности, английское местоимение he/she не вошли в исследования лингвистов, хотя, на самом деле, местоимения 3-го лица имеют общие корни с местоимением 1-го лица через существительное «яйцо». Это прекрасно видно из арамейского слов, обозначающих мужчину и женщину. Английские he, she происходят из арамейских «Ихь», «Ишь». Однако, местоимения английского языка имеют более древнее происхождение, нежели северо-семитское, а именно, древнеегипетское, в тоже время древнеегипетские слова основаны на славянских графемах, а не коптских, что даёт возможность читать древнеегипетские слова. Это видно из иероглифов древнеиндийского языка, которые описывают богиню Исиду. трон-хлеб-богиня- Ast - богиня Исида (др.-егип.) > SdtDv > sidij devj - сидящая дева, богиня (слав.). Здесь Исида не просто сидит, она сидит на яйце, иначе, высиживает яйцо. Это видно из следующего иероглифа Исиды. яйцо-хлеб-богиня - Ast - богиня Исида (др.-егип.) > JctDv > Isid/Jjkj deva - Йисида/яйко дева (слав.), то есть высиживающая яйцо дева, наседка, беременная женщина. коршун-трон-хлеб-дева- Ast - богиня Исида (др.-егип.) > KrSdt Dv > jaik Sdt deva > яйко сидеть дева (слав.)(инв. Kr, замена j/r) Исида и все её ипостаси - Иштар, Астарта - суть, образы Богини-матери, Матери рода, характерные для древнейших религий. Так, в Чатал-Хююке, древнейшем индоевропейском поселении найдены статуэтки Богини-матери, сидящей, как полагают многие исследователи на голове быка, в смысле рожающей быка. На самом деле Богиня мать рожает ребёнка, как это представлено в древнеегипетском иероглифе «рожаница». В отличие от Богини-матери, мужчина не высиживает плод, а носит семенники, поэтому он - he < herr - господин (герм.) < hr - самец (инд.-евр.)
Jk > ego (лат.)(редукция g/k) Jk > je (фр.) Jk > I (англ.)(удаление k) Jk > ic (староангл.)( редукция c/k, замена i/j) Jk > ich (нем.) Jk > jg > yo> (исп.)( редукция g/k, замена o/g) Jk > ego (греч.)(редукция g/k) Jk > aham (санскр.)( редукция h/k) Jk > jaz - азъ (старослав.)( редукция z/k) Mj > ani (ивр.)(замена ni/m) Jk > ik (гот.)(замена i/j) Jk > uk (хетт.)(удаление j) Mj > Ben (тур.)( редукция b/m) Mj > men > мен (кирг.) Mj > min > мин (тат.)
ti > tu (лат.)(замена u/i). ti > tu (франц.)(замена u/i). ti > tou > you (англ.)( замена t/y, ou/i). ti > du (нем.)( редукция d/t, u/i). ti > tú (исп.)( замена u/i). ti > tu (греч.)(замена u/i)/su (редукция s/t). ti > tv + am > (скр.)( замена v/i, добавление оконч. -am ). ti > тii > ты (старослав.)(добавка i). ti > it > at(a) (ивр.)(инв. ti, замена a/i, добавление оконч. -a). ti > þu (гот.)( замена þ/t, u/i).
jr > il (франц.)(замена i/j, редукция l/r). ih > he (англ.)(инв. ih). jr > er (нем.)( замена e/j). jr > él (исп.)( замена é/j, редукция l/r). jon > aut > aut-os (греч.)(замена au/j, t/n, добавление оконч. - os). jk > ih (ивр.)( редукция h/k).
jkn > elle (франц.)(замена e/j, ll/n). isha > she (англ.)( редукция s/j, замена h/n). isha > sie (нем.)(инв. isha). jkn > elia (исп.)( замена e/j, li/n). jona > aut > aut-oi (греч.)(замена au/j, t/n, добавление оконч. - oi). jkn > hi (ивр.)( замена h/j, i/n).
mi > no-s (лат.)(замена n/m, o/i, добавление оконч. - s). mi > no-us (франц.)(замена n/m, i/o, добавление оконч. - us). mi > we (англ.)( замена w/m, e/i). mi > wi-r (нем.)( замена w/m, добавление оконч. –r). mi > no-sotras (исп.)( замена замена n/m, o/i, добавление оконч. – so-tras), tris – три (праслав.). mi > eme-is (греч.)(замена e/i, пропуск e, добавление оконч. –is). mi > vay-ám (скр.)( замена v/m, ay/i, добавление оконч. –am). mi > мы (старослав.)(добавление i). mi > аna-xnu (ивр.)( замена n/m, пропуск a, добавление оконч. – xnu). mi > we-is (гот.)( замена w/m, e/i, добавление оконч. –is). mi > we-s (хет.)(замена w/m, e/i, добавление оконч. –s).
vi > vo-s (лат.)(замена o/i, добавление оконч. - s). vi > vo-us (франц.)(замена o/i, добавление оконч. - us). vi > yo-u (англ.)( замена y/v, o/i, добавление оконч. - u). vi > [v]i-hr (нем.)( удаление v, замена w/m, добавление оконч. –hr). vi > vo-sotras (исп.)( замена o/i, добавление оконч. – so-tras), tris – три (праслав.). vi > ese-is (греч.)(замена s/v, e/i, пропуск e, добавление оконч. –is). vi > yuy-ám (скр.)( замена y/v, uy/i, добавление оконч. –am). vi > вы (старослав.)(добавление i). vi > аte-m/n (ивр.)( замена t/v, e/i, пропуск a, добавление оконч. – m/n). vi > ju-s (гот.)( замена i/v, u/i, добавление оконч. –s).
joni > il,ells (франц.)(замена j/i, n/l, добавление оконч. - s). joni > they (англ.)( замена t/j, n/h, ey/i). joni > sie (нем.)( редукция s/j, удаление n, замена i/ie). joni > ell-os, ellas (исп.)( замена e/j, ll/n, добавление оконч. –os/as). joni > aut-es (греч.)(замена au/j, t/n, добавление оконч. –is). joni > hem (ивр.)( замена h/j, m/n).
Как мы видим, есть общие корни для личных местоимений именительного падежа данной группы языков - eja [ейа], ti [ты], jon [йон], jona [йона], mi [мы], vi [вы], joni [йони]. Это опровергает мнение лингвистов об отсутствии архетипа в местоимении 1-м лица именительного падежа.
В таблице 21 представлены личные местоимения в родительном и винительном падеже для группы самых распространённых языков.
Таблица 21
Продолжение таблицы 21
Формирование корней личных местоимений в родительном и винительном падеже :
mja > me (лат.)(замена e/ja), поскольку в лат. языке отсутствует славянская буква «Я», то буква «Я» была заменена на букву «I» и звук [ja] был замен на [i]. mja > me (лат.)(замена e/ja). mja > me (франц.)(замена e/ja). mja > me (англ.)( замена e/ja). mja > mich (нем.)( замена ich/ja). mja > me (исп.)( замена e/ja). mja > me (греч.)( замена e/ja). mja > ma + m (скр.)( замена e/ja, добавление оконч. –m). mja > мя (старослав.). mja > mi-k (гот.)( замена i/ja, добавление оконч. –k). mja > amu-k (хет.)(замена u/ja, пропуск a, добавление оконч. –k).
tja > te (лат.)(замена e/ja). tja > te (франц.)(замена e/ja). tja > you (англ.)( замена y/t, e/ja). tja > dich (нем.)( редукция d/t, замена ich/ja). tja > te (исп.)( замена e/ja). tja > se (греч.)( редукция s/t, замена e/ja). tja > tava, te (скр.)( замена v/j). tja > тя (старослав.). tja > þu-k (гот.)( заменаþ/t, u/ja, добавление оконч. –k). tja > tu-k (хет.)(замена u/ja, добавление оконч. –k).
jo > le (франц.)(замена l/j). jo > hi-m (англ.)( замена h/j, i/o, добавление оконч. –m). jo > ih-n, es (нем.)( замена h/j, добавление оконч. –n). jo > lo, la (исп.)( замена l/j).
nas > nos-tri, nos-trum (лат.)( добавление оконч. –tri, trum), tri – три (праслав.). nas > nous (франц.)( замена ou/a). nas > you (англ.)( замена y/n, ou/a). nas > uns (нем.)(перест. u/n). nas > nos (исп.). nas > mas (греч.)( замена m/n). nas > as-mán (скр.)(пропуск n, добавление оконч. –man). nas > uns, uns-is (гот.)( перест. u/n, добавление оконч. –is). nas > anz-as (хет.)( перест. a/n, редукция z/s, добавление оконч. –as).
vas > ves-tri, vestrum (лат.)( добавление оконч. –tri, trum), tri – три (праслав.). vas > vous (франц.)( замена ou/a). vas > us (англ.)( удаление v). vas > euch (нем.)( удаление v, редукция ch/s). vas > os (исп.)( удаление v). vas > sas (греч.)( замена s/n). vas > yus-mas, vah (скр.)( замена y/v, добавление оконч. –mas). vas > izw-is (гот.)( перест. i/z, инв. izw, замена v/w, добавление оконч. –is).
jij > les (франц.)( замена l/j, редукция s/j). jij > the-m (англ.)( замена t/j, h/i, добавление оконч. –m). jij > sie (нем.)( редукция s/j, замена e/j). jij > los (исп.)( замена l/j, редукция s/j).
Как мы видим, есть общие корни для личных местоимений родительного и винительного падежа данной группы языков - mja [мйа], tja [тйа], jo [йо], jej [йей], nas [нас], vas [вас], jij [йий]. Это опровергает мнение лингвистов об отсутствии архетипа в личных местоимениях родительного и винительного падежа.
В таблице 22 представлены личные местоимения в дательном падеже для группы самых распространённых языков.
Таблица 22
Продолжение таблицы 22
Формирование корней личных местоимений в дательном падеже :
mini > mihi (лат.)(замена h/i). mi > me (франц.)(замена e/i). mi > me (англ.)( замена e/i). mi > mir (нем.)( замена i/ir). mi > mou (исп.)( замена ou/i). mi > mou (греч.)( замена e/ja). mini > many + am, me (скр.)( замена y/n, добавление оконч. –am). mi > ми (старослав.). mi > mi-s (гот.)( замена i/ja, добавление оконч. –s). mi > amu-k (хет.)(замена u/i, пропуск a, добавление оконч. –k).
tibi > tibi (лат.) ti > te (франц.)(замена e/i). ti > you (англ.)( замена y/t, ou/i). ti > dir (нем.)( редукция d/t, замена ir/i). ti > te (исп.)( замена e/i). ti > sou (греч.)( редукция s/t, замена ou/i). tibi > tibhy-am, te (скр.)( замена hy/i, добавление оконч. –am). ti > ти (старослав.). ti > þu-k (гот.)( заменаþ/t, u/i, добавление оконч. –k). ti > tu-k (хет.)(замена u/i, добавление оконч. –k).
jem > lui (франц.)(замена l/j, добавление оконч. –m ). jem > hi-m (англ.)( замена h/j, i/e, добавление оконч. –m). jem > ih-m, es (нем.)( замена h/j, добавление оконч. –m). jem > le (исп.)( замена l/j, удаление m).
nam > nob-us (лат.)( редукция b/m, добавление оконч. –us). nam > nous (франц.)( замена ou/a, s/m). nam > you (англ.)( замена y/n, ou/a, s/m). nam > uns (нем.)(перест. u/n, замена s/m). nam > nos (исп.)(замена s/m). nam > mas (греч.)( замена m/n, s/m). nam > asmábhy-am, nah (скр.)(пропуск as, замена m/n, редукция b/m, добавление оконч. –am). nam > þus (гот.)( замена þ/n, s/m). nam > tuk (хет.)( .)( замена t/n, k/m).
vam > vobus (лат.)( редукция b/m, добавление оконч. –us). vam > vous (франц.)( замена ou/a, s/m). vam > us (англ.)( замена v/u, s/m). vam > euch (нем.)( замена v/u, замена ch/m). vam > les (исп.)( замена l/v, s/m). vam > sas (греч.)( замена s/v, s/m). vam > yusmabhyam, vah (скр.)( замена y/v, h/m, добавление оконч. –am). vam > izw-is (гот.)( перест. i/z, замена z/v, w/m, добавление оконч. –is).
jim > leur (франц.)( замена l/j, r/m). jim > the-m (англ.)( замена t/j, h/i, добавление оконч. –m). jim > ihn-en (нем.)( редукция h/j, замена n/m, добавление оконч. –en. jim > les (исп.)( замена l/j, s/m).
Как мы видим, есть общие корни для личных местоимений дательного падежа данной группы языков - mini, mi [мини, ми], tibi, ti [тиби, ти], jem [йем], jej [йей], nam [нам], vam [вам], jim [йим]. Это опровергает мнение лингвистов об отсутствии архетипа в личных местоимениях родительного и винительного падежа.
Притяжательные местоимения
В таблице 23 представлены притяжательные местоимения для группы самых распространённых языков.
Таблица 23
Формирование корней притяжательных местоимений :
moj > meus (лат.)(замена eu/o, редукция s/j) moj > mon(франц.)( замена n/j). moj > my (англ.)( замена y/j)/mine (замена n/j). moj > mein (нем.)( замена n/j). moj > mi (исп.)( замена i/j). moj > mou (греч.)( замена eu/o).
mnoja > mea (лат.)( замена e/j, удаление no). mnoja > ma (франц.)( удаление noj). mnoja > my (англ.)( замена y/ja)/mine (перест. n/o, удаление ja). mnoja > meine (нем.)( перест. n/o, удаление j, замена e/a).
tvoj > tuus (лат.)( замена u/v, редукция s/j). tvoj > ton (франц.)( перест. n/o, замена n/v, удаление j). tvoj > your (англ.)( замена y/v, r/j, удаление t). tvoj > dein (нем.)( перест. n/v, замена n/v, редукция d/t). tvoj > tus (исп.)( замена u/v, редукция s/j). tvoj > sou (греч.)( редукция s/t, замена u/v).
svoj > suus (лат.)( замена u/v, редукция s/j). svoj > sebij > samij > some (англ.)( замена m/b, e/j). svoj > su (исп.)( замена u/v, удаление j).
nashij > noster (лат.)( замена r/j, редукция st/sh). nashij > notre (франц.)( замена t/sh, r/j). nashij > our (англ.)(удаление n, замена r/j, удаление sh). nashij > unser (нем.)( перест.a/n, редукция s/sh, замена r/j). nashij > nuestr-o (исп.)( редукция st/sh, замена r/j, добавление оконч. –о). nashij > mas (греч.)( замена m/n, редукция s/sh, удаление оконч. –ij).
vashij > vester (лат.)( замена r/j, редукция st/sh). vashij > votre (франц.)( замена t/sh, r/j). vashij > your (англ.)(замена y/v, r/j, удаление sh). vashij > euer (нем.)( перест.v/a, замена u/v, r/j). vashij > sas (греч.)( замена s/v, редукция s/sh, удаление оконч. –ij).
joj > leur (франц.)( замена l/j, r/j). joj > his (англ.)(замена h/j, редукция s/j). joj > jojn-ij > sein (нем.)(замена i/j, редукция s/j). joj > lo (исп.)( замена l/j). joj > tou (греч.)( замена t/j, u/j).
jej > leur-s (франц.)( замена l/j, r/j, добавление оконч. –s ). jej > their (англ.)(замена th/j, r/j). jej > ihr (нем.)(замена i/j, r/j). jej > la (исп.)( замена l/j). jej > tis (греч.)( замена t/j, редукция s/j).
jij > leur (франц.)( замена l/j, r/j). jij > her (англ.)(замена h/j, r/j). jij > ihr (нем.)(замена i/j, r/j). jij > su (исп.)( редукция s/j, удаление j). jij > tous (греч.)( замена t/j, редукция s/j).
Как мы видим, есть общие корни для притяжательных местоимений данной группы языков - moj [мой], tvoj [твой], svoj [свой], nashij [наший], vashij [ваший], joj [йой], jej [йей], jij [йий]. Это опровергает мнение лингвистов об отсутствии архетипа в притяжательных местоимениях.
Указательные местоимения
Указательные местоимения в исследуемой группе иностранных языков очень развиты, различаясь известными оттенками значения, но все они восходят к архетипам праязыка, указывая на близкий предмет (слав. корень «близ-кий»), на соседний предмет (слав. корень «сосед-ний») и на наиболее отдалённый предмет (слав. корень «даль-ний»). В таблице 24 представлены указательные местоимения для группы самых распространённых языков.
Таблица 24
Формирование корней указательных местоимений :
eto > ist-ĕ (лат.)(вставка s, замена ĕ/o). blizk > hĭc (лат.)(инв. blizk, замена c/b, i/l, редукция h/k, удаление z). blizka > haec (лат.)(инв. blizka, замена замена c/b, i/l, редукция h/k, удаление z). blizko > hŏc (лат.)(инв. blizka, замена замена c/b, i/l, редукция h/k, удаление z). sosed-ij > ist-ĕ (лат.)( удаление s, редукция t/d, замена ĕ/ij). sej > ĭs (лат.)(инв.sej, замена i/j). sijo > ĭd (лат.)(инв.sijo, замена d/o, i/j). dalej > illĕ (лат.)( удаление d, удвоение l). takoj > talis (лат.)( замена l/k, редукция s/j). sej > ce (франц.)( редукция c/s, удаление j). sej > cet (франц.)( редукция c/s, замена t/j). blizk > celui-ci (франц.)( замена c/b, удаление z, редукция c/k). dalej > celui-la (франц.)( замена c/d, l/j). eto > this (англ.)( удалени e, s, замена th/t, i/o). sej > this (англ.)( инв. sej, замена th/j). tot > that (англ.)( замена th/t, a/o). takoj > such a (англ.)( редукция s/t, ch/k). blizk > dieser (нем.)( замена d/b, i/l, r/k, редукция s/z). dalej > dalnej > jéner (нем.)( замена j/d, e/l, r/j). takoj > sólcher редукция s/t, ch/k, вставка l, замена r/j). sosed-ij > iste (исп.)( удаление s, редукция t/d, замена e/ij). dalej > dalnej > aquel (исп.)( перест. a/q, замена q/d, n/u, l/j, удаление l). eto > aut-os (греч.)( замена au/e, вставка –os). tot > tout-os (греч.)( вставка –os).
Общие корни для указательных местоимений данной группы языков формируются на основе праславянского языка : eto [это], blizk [близк-ий], sosedij [соседний], sej [сей], dalej [дальний] и др.
Вопросительные местоимения
Вопросительные местоимения в исследуемой группе иностранных языков употребляются как прилагательные в значении который, -ая, -ое ?, какой, -ая, -ое ? и происходят от одного исторического праславянского корня koj [кой]. По форме представления вопросительные местоимения совпадают в основном с относительными местоимениями (см. табл. 23).
Неопределённые местоимения
Неопределённые местоимения представляют собой те же вопросительные или относительные местоимения с присоединением к ним частиц, придающих значение неопределённости. Неопределённые местоимения в предложении выступают в роли существительного или прилагательного. Частицы, выражающие значение неопределённости основаны на архетипах славянских корней «кой» – koj, «дальний» dalij -, «ни быти» - ni biti, «дружий» drujij - , «каждый» kagd -, «один» odn - , «любый» - lubij, «вольный» -volnij, «некий» - nekij, «не-мужий» ne-mugj-, «ни-чей» ni-chij-, «ни-малый» ni-malij-, «весь», «всий» ves, vsij, «обои» oboj, «один» odn, «самый» samij. В таблице 25 представлены неопределённые местоимения для группы самых распространённых языков.
Таблица 25
Формирование корней неопределённых местоимений в иностранных языках:
drujij-koj > alĭ-quĭs – другой-кой (лат.)( редукция qu/k, l/r, s/j, удаление d). koj-ni-biti > koj-nibud > quĭs-piam – кой-нибудь (лат.)( редукция qu/k, p/b, инв. nibud, замена m/ni). koj-nekij > quis-quam – кой-некий (лат.)( редукция qu/k, инв. nekij, замена m/n). kagdij > quisque – каждый (лат.)( редукция qu/k, замена s/g, q/d). odn-kajdij > unus-quisque – один-каждый (лат.)( редукция qu/k, замена s/g, q/d, удаление d). koj-volnij > quid-vis – кой-вольный (лат.)( редукция qu/k, замена i/l, удаление n). koj-lubij > qui-lĭbet– кой-любый (лат.)( редукция qu/k). koj-bi-nekij > qui-c-unque – кой-бы-некий (лат.)( редукция qu/k, замена c/b, перест. n/e). ali > ali-us – али/или (лат.)(добавление оконч. -us). drujij > ali-us – дружий (лат.)( редукция l/r, добавление оконч. –us, удаление d). ne-mugj > ne-mō – не-мужий/умный (лат.)( замена ō/g). ni-chij > ni-hil – ни-чей (лат.)( редукция h/ch, замена l/j). ves > tote – весь (лат.)( замена t/v, редукция t/s). oboj > ambo – обои (лат.)( редукция m/b). odn > un-us – один (лат.)(удаление d). samj > ipsĕ – самый (лат.)(инв. sam, редукция p/m, замена i/j).
koj- nekij > quel-que-un – кой-некий (франц.)( редукция qu/k, замена l/j, инв. nekij). koj- nekij > certain – кой-некий (франц.)( редукция с/k, замена r/j, инв. nekij, замена t/j, удаление k). kagdij > chac-un – каждый-один (франц.)( редукция ch/k, c/g, удаление dij, добавление добавление un). drujij > autre – дружий (франц.)(инв. drujij, замена e/d, t/j). ni-koj > n-ul – ни-кой (франц.)( удаление k, i). ni-chij > r-ien – ни-чей (франц.)(инв. ni-ch-ij, замена r/ch). ves > tout – весь (франц.)( замена t/v, редукция t/s). odn > le un – один (франц.)( удаление d, добавление le). samj > même - самый (франц.)( удаление s, замена e/j).
nekij-ni-biti > necij-ni-bud > som- body – некий-ни-будь (англ.)(инв. som, инв. nibud, замена ni/m, y/v-n, b/d, d/b, o/c-k, редукция s/j). kagdij- biti > kagdij-bud > every-body – каждый-буди (англ.)( замена e/c-k, v/j, r/j, удаление d). odn-kajdij > every-one – каждый-один (англ.)( удаление d). lubij > any – любой (англ.)( удаление l, замена n/b). ni-biti > nobody – ни-будь (англ.)( редукция d/t). ni-odn > no one – ни-один (англ.)( удаление d). ni-chij > no-thing – ни-чей (англ.)( редукция th/ch, ng/j). ves > all – весь (англ.)( замена l/v, l/t-s, перест. a/l ). kagdij-ves > every-thing – каждый-весь (англ.)( инв. ves, редукция v/ng, th/s). oboj > both – обои (англ.)( удаление j, редукция th/j). odn > one – один (англ.)( удаление d). samj > same – самый (англ.)( замена e/j).
koj-nekij > ir-gend – кой-некий (нем.)( удаление k, замена r/j, инв. gen, редукция g/k). koj-nekij > jémand - кой-некий (нем.)( удаление k, замена m/n, n/k, j/d). kagdij > jéder – каждый (нем.)( удаление k, редукция j/g, замена r/j). drugij > derándere > der ándere – другой (нем.)( замена a/u, d/g, r/j). ne-mugj > nie-mand – ни-мужний (нем.)( замена nd/gj). ni-koj > kéi-ner – ни- кой (нем.)( замена i/j, добавление ner). ni-chij > nichts – ни-чей (нем.)(замена t/i, редукция s/j). ves > all – весь (нем.)( замена l/v, l/t-s, перест. a/l ). oboj > beide – обои (нем.)( удаление o, редукция d/j). odn > eine – один (нем.)( удаление d). samj > selbst – самый (нем.)( редукция b/m, st/j).
koj- nekij > al-guien – кой-некий (исп.)( удаление k, замена l/j, инв. guien, редукция g/k). kagdij > cada – каждый (исп.)( удаление g, j, редукция c/k). drugij > otro – другой (исп.)(инв. drugij, замена o/d, t/g). ni-koj > na-die - ни- кой (исп.)( замена k/q-d, e/j). ni-chij > na-da - ни-чей (исп.)(замена d/ch). ves > todo - весь (исп.)( замена t/v, d/s). oboj > ambos - обои (исп.)( редукция m/b, s/j, удвоение b). odn > un-o - один (исп.)( удаление d). samj > mismo - самый (исп.)(перест. m/s).
lubij-ni-biti > opoi-os-dipote – любой-ни-будь (греч.)( удаление l, редукция p/b, t/d, замена p/v). koj-lubij > ka-poios – кой-любой (греч.)( удаление j, l, редукция p/b, t/d, замена d/n). kagdij > kathe – каждый (греч.)( замена th/d, e/j). drujij > all-os – дружий (греч.)( удаление d, редукция l/r, замена s/j). ni-koj > ka-ne-is - кой-не (греч.)( перест. ni/koj, удаление j). ni-malj > ti-pota – ни-малый (греч.)( замена t/n, t/j, редукция p/m). ves > ol-as - весь (греч.)( замена l/v, удаление s). oboj > oi du-o - обои (греч.)( замена d/b). odn > en-as - один (греч.)( удаление d). samj > o idi-os – самый (греч.)( удаление s, замена d/m, i/j). samj > out-os – самый (греч.)( удаление s, замена u/n-m, t/j).
Примечание : Английские слова body – «тело», «человек», thing – «вещь», «предмет» на самом деле происходят от славянских корней ni-biti – «не быти» и ni-chij – «ни-чей» из-за фонетического сходства. В самом деле, словосочетание everybody – «»все», «каждый» , «всякий» дословно переводится «каждое тело», «каждый человек», что в общем-то удивляет по своему содержанию, в то время как славянский перевод «каждый нибудь» вполне содержательно.
Числительные
В состав любого иностранного языка входят, как правило, количественные и порядковые числительные. Числительные в иностранных языках имеют общие фонетические основы, заимствованы из праславянского языка и перешедшие в латинский язык, а затем распространённые на другие иностранные языки. Числительные праславянского языка полностью сохранились в старославянском языке : odn – един, dva – два, tri – три, chatir – четыре, pjat – пять, НО, sed – сидети (старослав. шесть), sem – семя, семья (старослав. седмь), oko - око (старослав. осмь, русск. восемь) и другие.
Римские цифры
Римские цифры, на мой взгляд, происходят из языка жестов. В до-римскую эпоху существовал естественный дефицит материала для письма. Бумаги не было, папирус и пергамент были редкими в быту и сложными в производстве. Как народ мог изъясняться на рынке, купцы разных стран друг с другом при купле-продаже и обмене товаром ? Самый естественный и простой способ - язык жестов. Причем в качестве жестов самым удобным предметом являются кисти рук. В этом смысле привлекает внимание латинское слово genti, которое лингвисты выводят от centum – сотня. Однако, смею предположить, что genti происходит от латинского слова gestum – обсуждать (жестикулировать), которое является производным слав. слова кисть. Здесь же gnita - раб (лат.) – гнуть, сгибаться, гнида (слав.). Чтобы понять смысл слова кисть необходимо рассмотреть слово локоть – в латинской транскрипции locot / с инверсией и редукцией гласных socol – корень s-c-l -складывать (слав.). Возможно, отсюда и gladis/s-clad – складывать, «меч-(с)кладинец». В ходе рабочего процесса рука складывается в локте и распрямляется. Чтобы ударить мечем надо сложить руку и распрямить. Если локоть складывается, то кисть сгибается. В итоге получаем genti (лат.) – кисть (слав.) Действительно, кисть имеет пять пальцев – это единица счета пятерками. Две кисти – десятка (decem (лат.)/ de-gen/ de- genti). Рассмотрим римские цифры в языке жестов: 1 - I – один палец кисти. 2- II – два пальца кисти. 3 - III – три пальца кисти. 4 - IV – здесь, казалось бы, должна быть цифра IIII, но эта позиция занята цифрой М – mill (лат.) – тысяча. Поэтому имеем вычитание из пяти – IV это один палец одной кисти и галочка другой кисти. Галочка (V) – жест с одним отогнутым большим пальцем и четырьмя сложенными в другую сторону. 5 -V – галочка. 6 - VI – галочка + один палец другой кисти. 7 - VII - галочка + два пальца другой кисти. 8 - VIII - галочка + три пальца другой кисти. 9 - IX – один палец одной кисти и две кисти сложенные крест накрест. 10 - X - две кисти сложенные крест накрест. 20 - XX – два раза две кисти сложенные крест накрест (viginti/ dvi –ginti). 30 - XX X– три раза две кисти сложенные крест накрест (triginti/ tri –ginti). 50 L – рука сложенная пополам. 100 - С – кольцо из двух пальцев. 500 – D – домик из двух соприкасающихся пальцев обеих рук в виде треугольника. М – ладонь вверх с согнутым большим пальцем (изображение буквы М. буква М состоит из четырех черт, поэтому нет цифры IIII). В итоге мы имеем систему счета, которая полностью осмысливается в славянской трактовке.
В таблице 27 представлены неопределённые местоимения для группы самых распространённых языков.
Таблица 27
Формирование корней колличественных числительных в иностранных языках:
odn > un-us (лат.)(удаление d). odn > un (франц.)(удаление d). odn > one (англ.)(удаление d). odn > ein (нем.)(удаление d). odn > un-o (исп.)(удаление d). odn > ena (греч.)(удаление d).
dva > duo (лат.)(замена u/v). dva > deu-x (франц.)(замена u/v). dva > two (англ.)(редукция t/d, замена w/v). dva > zwei (нем.)(замена z/d, w/v). dva > do-s (исп.)( удаление v). dva > duo (греч.)(замена u/v).
tri > tre-s (лат.). tri > troi-s (франц.). tri > three (англ.)( замена th/t). tri > drei (нем.)( редукция d/t). tri > tre-s (исп.). tri > tria (греч.).
Число 4 - «четыре» образовалось от основы праязыка chatir – «четыре». Этимология слова «четыре», вероятно восходит к славянским словам cherta – «черта» и storona -«сторона», то есть замкнутое пространство, очерченное углами в отличие от круга.
chatir > quattuor (лат.)( редукция qu/ch, удвоение t). chatir > quatre (франц.)( редукция qu/ch). chatir > four (англ.)(удаление ch, замена f/t). chatir > vier (нем.)( удаление ch, замена v/t). chatir > cuatro (исп.)( редукция c/ch). chatir > tessera (греч.)( редукция tes/ch, s/t).
Число 5 - «пять» образовалось от разных основ праязыка pjat – «пять», «пята» и kon – «кон», «конец», тем не менее имея общий смысл «пять пальцев ноги или руки».
pjatk > quinque – пять (лат.)( замена qu/p, t/n, редукция qu/k). kon > quinque – конец (лат.)( редукция qu/k, qu/c). pjatk > cinq – пяток (франц.)( замена с/p, t/n, редукция q/k). kon > cinq – конец (франц.)( редукция с/k, q/c), примечание : слово cinq читается как прямо, так и инверсно в занчении «конец». pjat > five – пята (англ.)( редукция f/p, замена v/j, удаление t). pjatk > fünf – пята (нем.)( редукция f/p, f/k, замена u/j, n/t). kon > cinc-o – конец (исп.)( редукция c/k). pjat > pente – пяток (греч..)( замена e/j, k/n, перест. t/k).
Число 6 - «шесть» образовалось от основы праязыка sed – «сидети», zad – «зад».
sed > sex (лат.)( редукция x/d). sed > six (франц.)( редукция x/d). sed > six (англ.)( редукция x/d). sed > sech-s (нем.)( редукция ch/d). sed > seis (исп.)( редукция s/d). sed > exi (греч.)( удаление s, редукция x/d).
Число 7 - «семь» образовалось от основы праязыка sem – «семья», «семя», как признак целого из чего формируются составные части. Например, семь оконечностей тела человека, семь дырок в теле человека, семь цветов, семь нот, семя, как рождение всего живого. Поэтому, число 7 считалось в древности сакральным.
sem > sept-em (лат.)( редукция p/m). sem > sept (франц.)( редукция p/m). sem > seven (англ.)( замена vn/m). sem > sieb-en (нем.)( редукция b/m). sem > siete (исп.)( редукция t/m). sem > efta (греч.)( замена s/f, редукция t/m).
Число 8 - «восемь» от основы праязыка oko «око», okom «окоём». Вероятно, от двух глаз, «очи», два круга, напоминающие цифру 8 - «восемь». oko> oct-o (лат.)( редукция c/k). oko > hu-it (франц.)( удаление o, редукция h/k). oko > eigh-t (англ.)( редукция g/k, замена ei/o). oko > ach-t (нем.)( редукция ch/k). oko > och-o (исп.)( редукция ch/k). oko > okt-o (греч.).
Число 9 - «девять» от основы праязыка nov – новый.
nov > nov-em (лат.). nov > neuf (франц.)( редукция f/v). nov > nine (англ.)( замена n/v). nov > neun (нем.)( замена n/v). nov > nueve (исп.). nov > ennia (исп.)( замена n/v).
Число 10 - «десять» от основы праязыка dve-ruk – «две руки». В древности первой единицей счёта было число 5. Поэтому две пятёрки (две руки) – десять. В старославянском языке основа dve-ruk трансформировалась в dve-kist – «две-кисти», то есть dve-sjat – «де-сять».
dve-ruk > dec-em (лат.)(удаление v, r, редукция c/k). dve-ruk > dix (франц.)( удаление v, r, редукция x/k). dve-ruk > ten (англ.)( удаление v, r, редукция t/d, замена n/k). dve-ruk > zehn (нем.)( удаление v, r, замена z/d, n/k). dve-ruk > diez (исп.)( удаление v, r, замена z/k). dve-ruk > deka (греч.)( удаление v, r).
Десятки в иностранных языках сформировались от основы праязыка kist – «кисть», gnutij – «гнутый» (две согнутые крестом кисти).
dve-gnutij > viginti – две-гнутые (лат.)(удаление d). dve-gnutij > vingt – (франц.)(удаление d, перест. n/g). dve-gnutij > twenty (англ.)( редукция t/d, замена w/v, удаление g). dve-gnutij > zwanzig – (нем.)( замена z/d, w/v, перест. n/z, редукция z/g). dve-gnutij > veinte (исп.)( удаление d, g). dve- kisti > eikosi (греч.)( удаление d, t).
Сотни в иностранных языках сформировались от основы праязыка sotnja – «сотня».
sotnja > cent-um (лат.)( редукция c/s, перест. n/t). sotnja > cent (франц.)( редукция c/s, перест. n/t). sotnja > hundr-ed (англ.)(перест. n/d, редукция h/s, d/t, замена r/j). sotnja > hunder-t (нем.)(перест. n/d, редукция h/s, d/t, замена r/j). sotnja > ciento (исп.)( редукция c/s, перест. n/t). sotnja > ekato (греч.)( редукция k/s, удаление n).
Тысячи в иностранных языках сформировались от основы праязыка tima – «тьма» и в более поздней форме от старославянского языка tisjashta – «тысяшта», соврем. русский – «тысяча».
tima > mille (лат.)(инв. tima, замена l/t). tima > mille (франц.)(инв. tima, замена l/t). tisjacha > thousand (англ.)( замена nd/ch). tisjacha > tausend (нем.)( замена nd/ch). tima > mil (исп.)(инв. tima, замена l/t). tima > xilia (исп.)(инв. tima, замена m/x, l/t).
Продолжение следует
|